Introduction
This page presents how Tapaal do cope efficiently with the Liveness examination face to the other participating tools. In this page, we consider «Known» models.
The next sections will show chart comparing performances in terms of both memory and execution time.The x-axis corresponds to the challenging tool where the y-axes represents Tapaal' performances. Thus, points below the diagonal of a chart denote comparisons favorables to the tool while others corresponds to situations where the challenging tool performs better.
You might also find plots out of the range that denote the case were at least one tool could not answer appropriately (error, time-out, could not compute or did not competed).
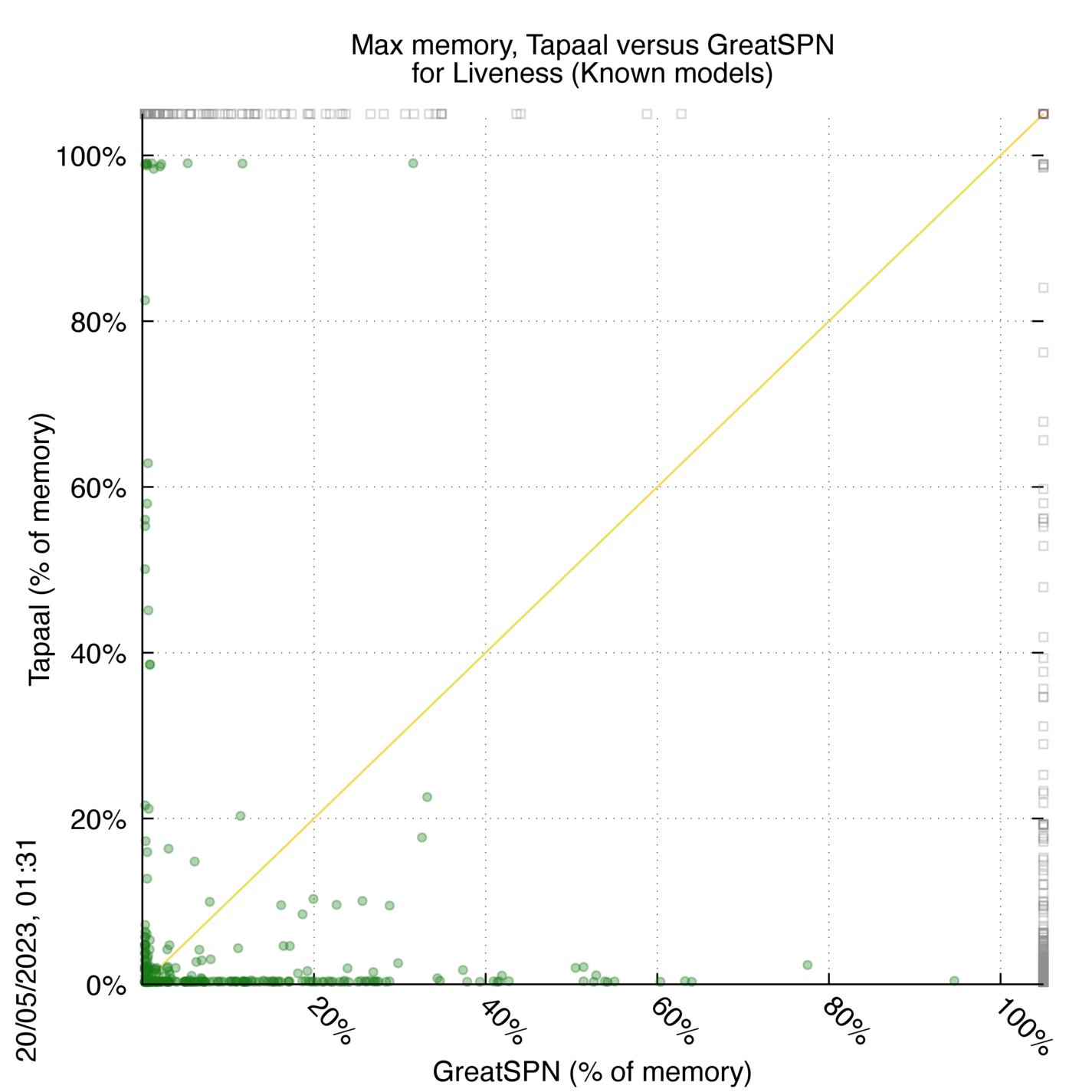
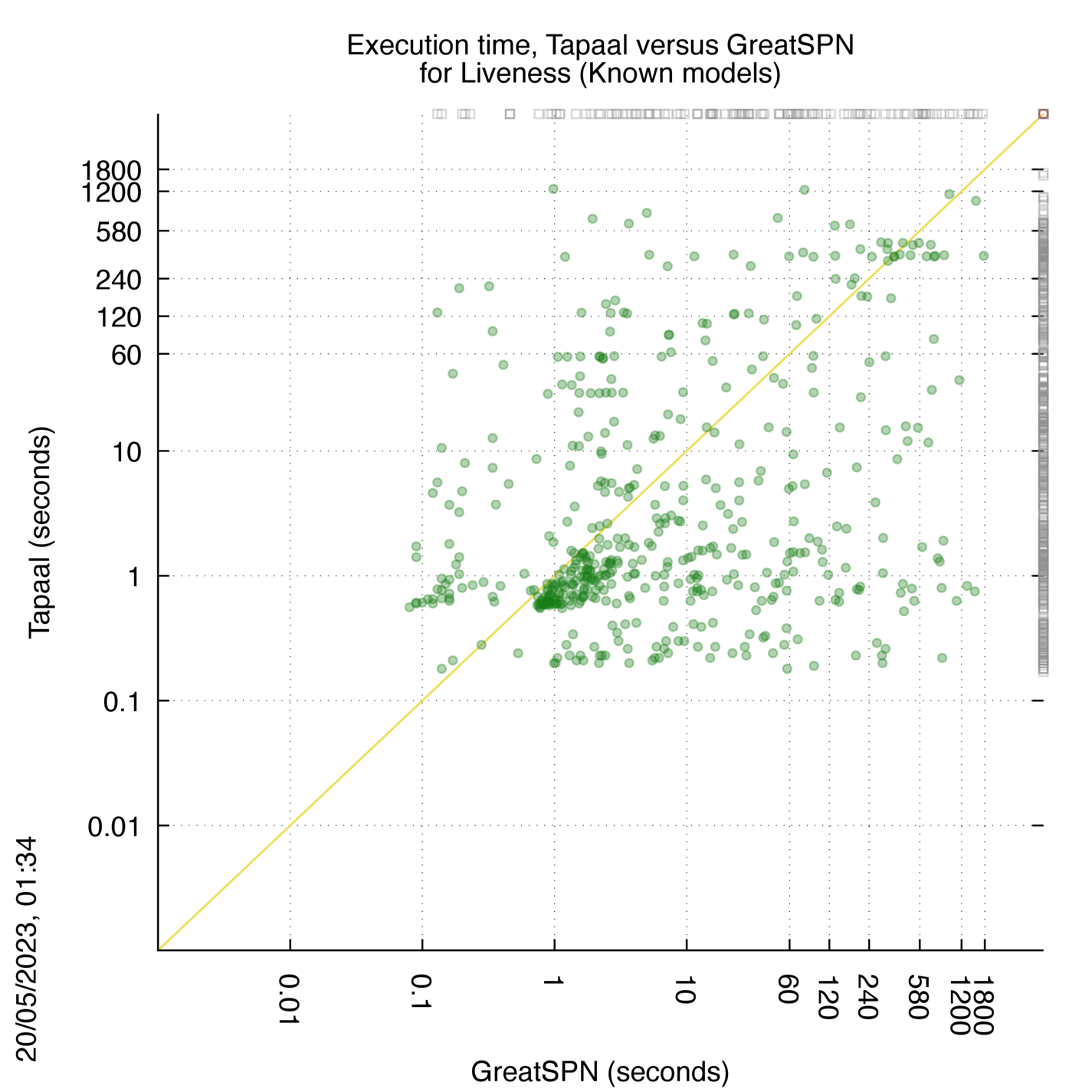
Tapaal versus GreatSPN
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for GreatSPN, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to GreatSPN are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | GreatSPN | Both tools | Tapaal | GreatSPN | ||
| All computed OK | 677 | 117 | 508 | Smallest Memory Footprint | ||
| Tapaal = GreatSPN | — | — | 0 | Times tool wins | 1091 | 211 |
| Tapaal > GreatSPN | — | — | 0 | Shortest Execution Time | ||
| Tapaal < GreatSPN | — | — | 0 | Times tool wins | 1023 | 279 |
| Do not compete | 0 | 0 | 0 | |||
| Error detected | 0 | 1 | 0 | |||
| Cannot Compute + Time-out | 118 | 677 | 314 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than GreatSPN,
denote cases where Tapaal
computed more values than GreatSPN,
![]() denote cases where Tapaal
computed less values than GreatSPN,
denote cases where Tapaal
computed less values than GreatSPN,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, GreatSPN wins when points are above the diagonal.
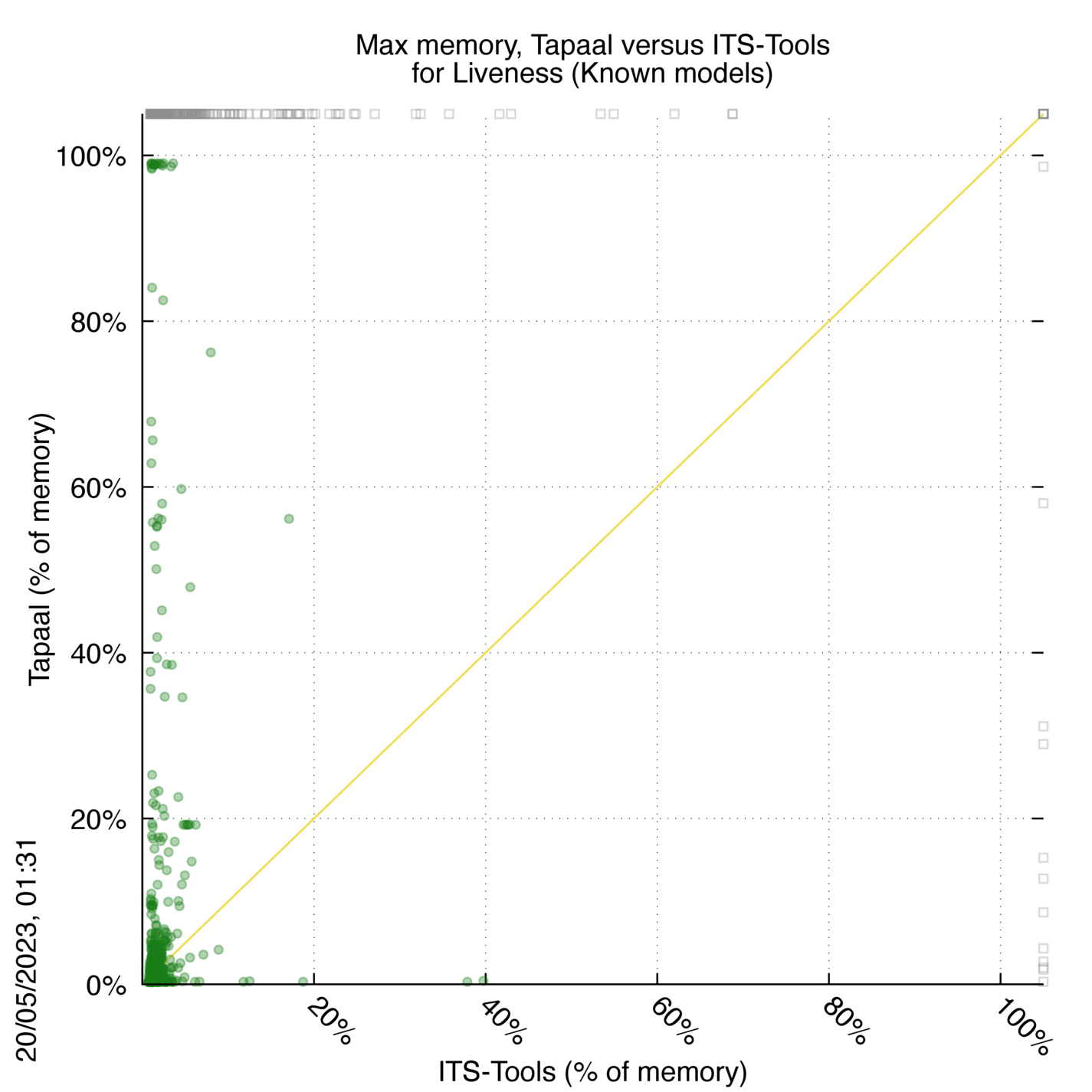
Tapaal versus ITS-Tools
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for ITS-Tools, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to ITS-Tools are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | ITS-Tools | Both tools | Tapaal | ITS-Tools | ||
| All computed OK | 12 | 332 | 1173 | Smallest Memory Footprint | ||
| Tapaal = ITS-Tools | — | — | 0 | Times tool wins | 859 | 658 |
| Tapaal > ITS-Tools | — | — | 0 | Shortest Execution Time | ||
| Tapaal < ITS-Tools | — | — | 0 | Times tool wins | 574 | 943 |
| Do not compete | 0 | 0 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 332 | 12 | 100 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than ITS-Tools,
denote cases where Tapaal
computed more values than ITS-Tools,
![]() denote cases where Tapaal
computed less values than ITS-Tools,
denote cases where Tapaal
computed less values than ITS-Tools,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, ITS-Tools wins when points are above the diagonal.

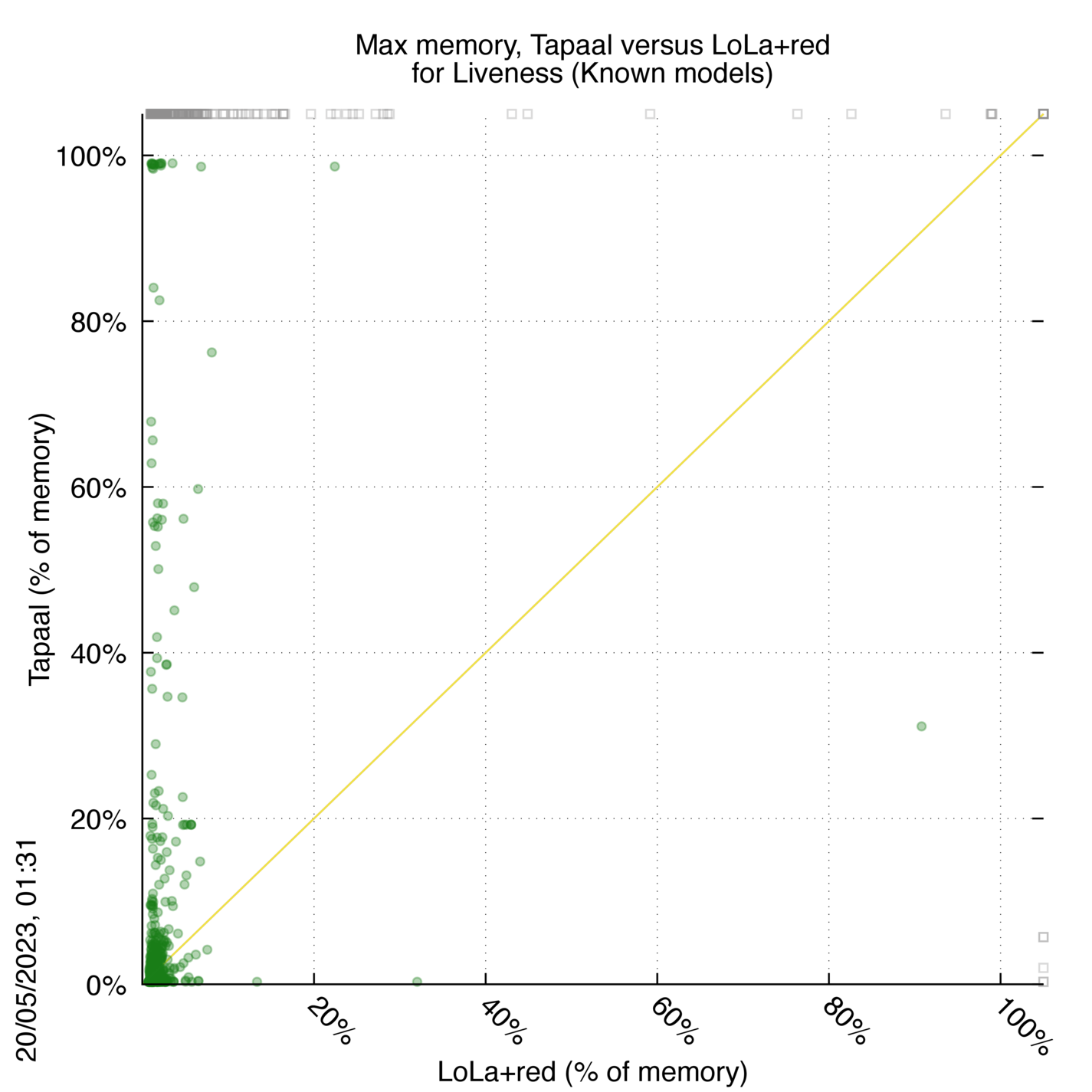
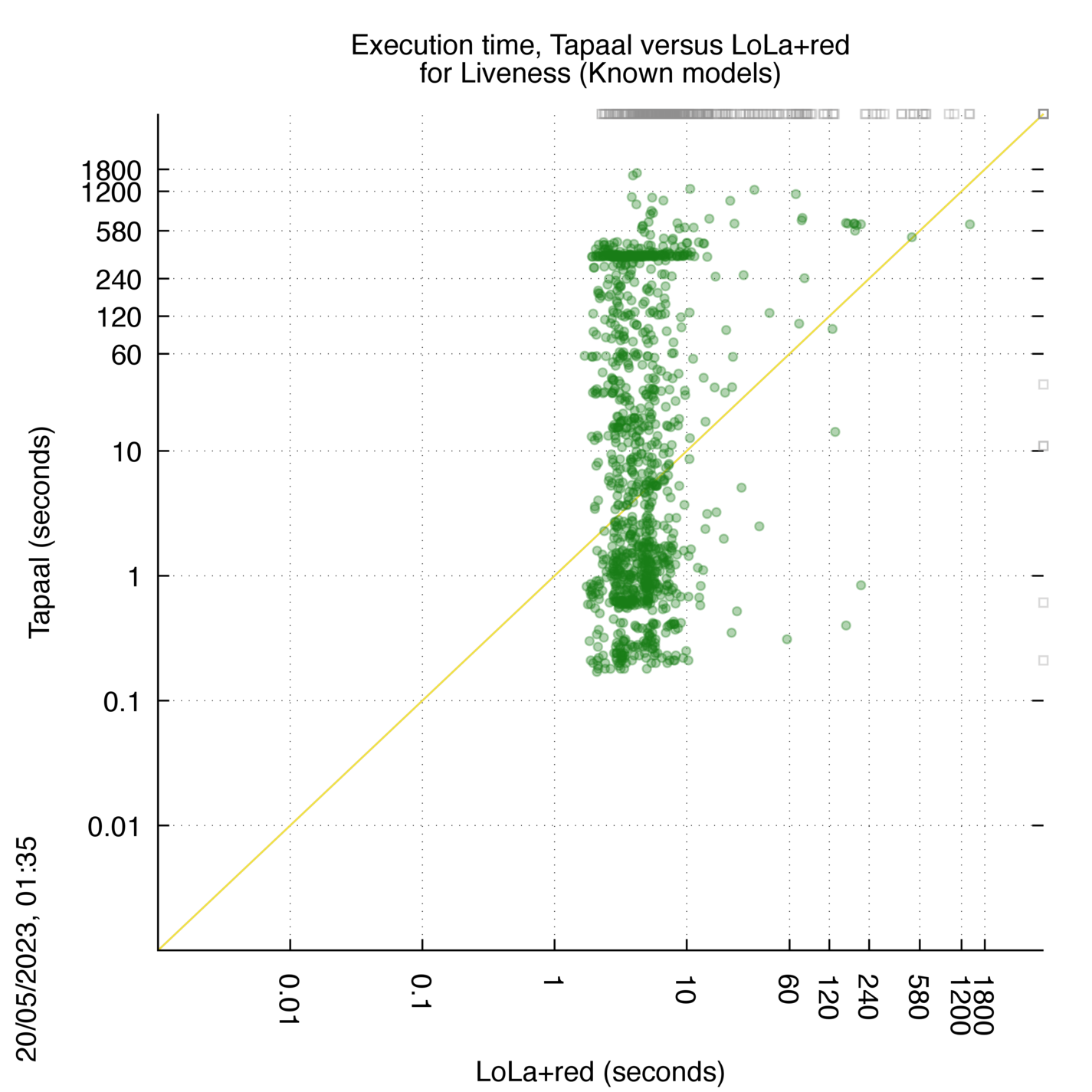
Tapaal versus LoLa+red
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for LoLa+red, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to LoLa+red are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | LoLa+red | Both tools | Tapaal | LoLa+red | ||
| All computed OK | 5 | 323 | 1180 | Smallest Memory Footprint | ||
| Tapaal = LoLa+red | — | — | 0 | Times tool wins | 850 | 658 |
| Tapaal > LoLa+red | — | — | 0 | Shortest Execution Time | ||
| Tapaal < LoLa+red | — | — | 0 | Times tool wins | 571 | 937 |
| Do not compete | 0 | 0 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 323 | 5 | 109 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than LoLa+red,
denote cases where Tapaal
computed more values than LoLa+red,
![]() denote cases where Tapaal
computed less values than LoLa+red,
denote cases where Tapaal
computed less values than LoLa+red,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, LoLa+red wins when points are above the diagonal.
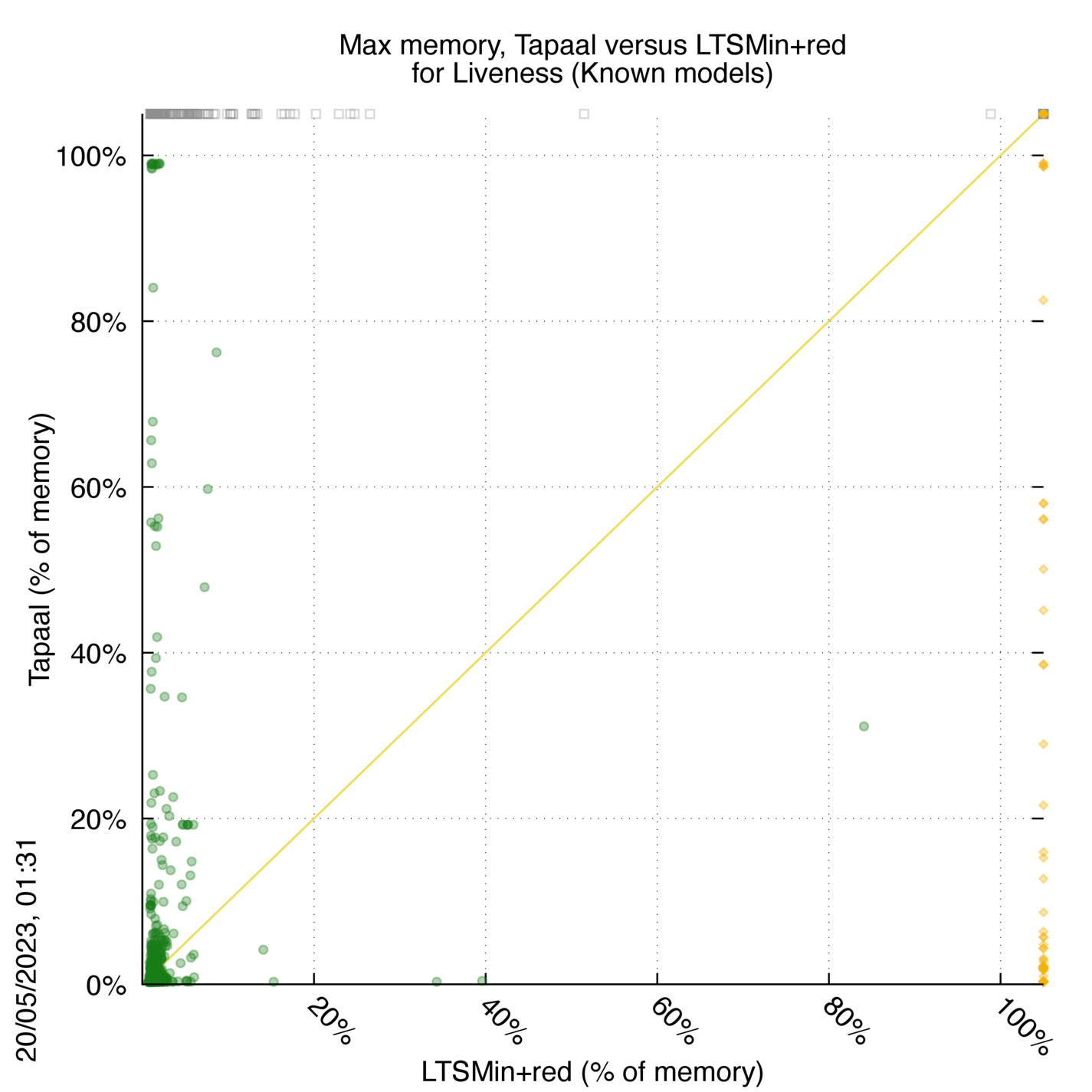
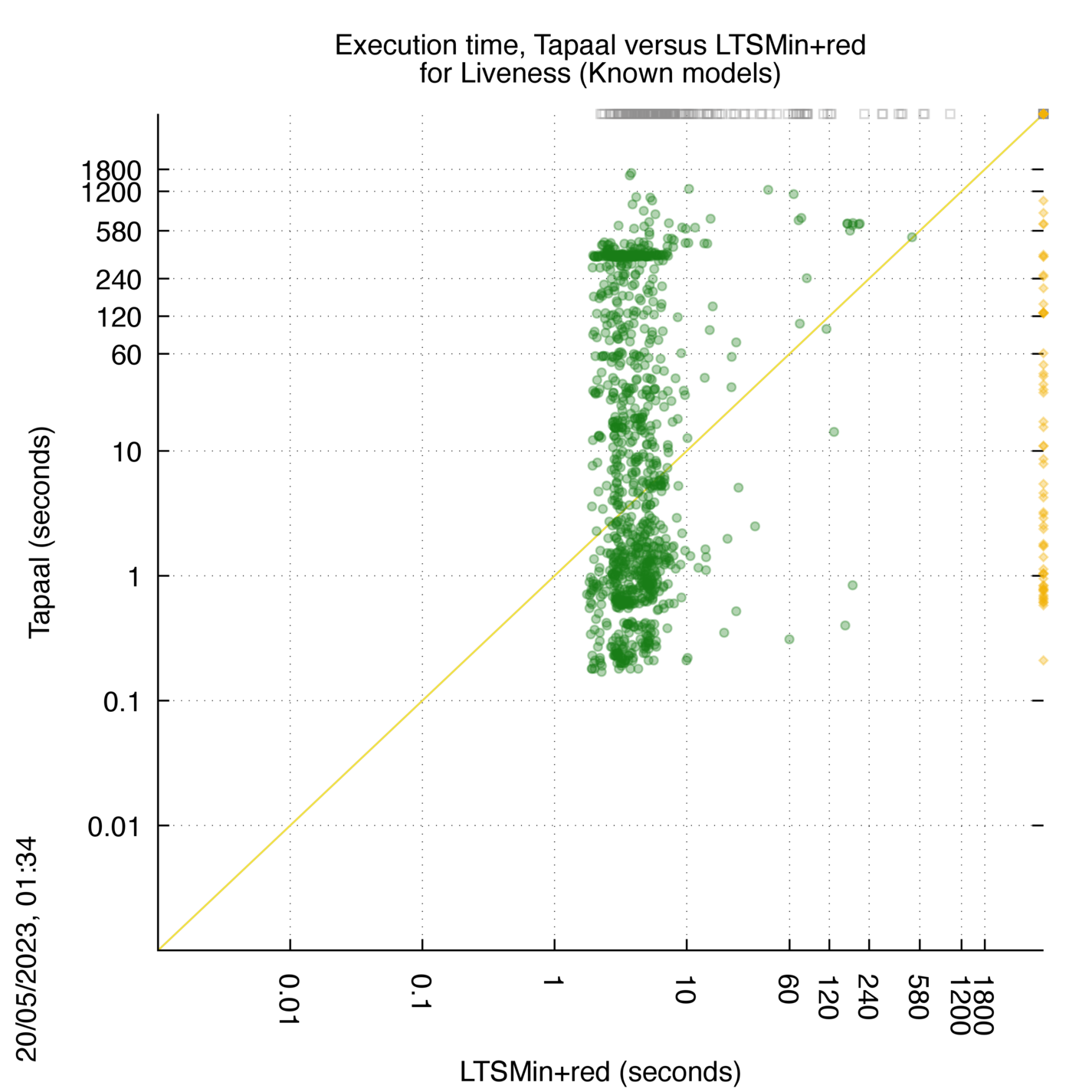
Tapaal versus LTSMin+red
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for LTSMin+red, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to LTSMin+red are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | LTSMin+red | Both tools | Tapaal | LTSMin+red | ||
| All computed OK | 62 | 228 | 1123 | Smallest Memory Footprint | ||
| Tapaal = LTSMin+red | — | — | 0 | Times tool wins | 880 | 533 |
| Tapaal > LTSMin+red | — | — | 0 | Shortest Execution Time | ||
| Tapaal < LTSMin+red | — | — | 0 | Times tool wins | 596 | 817 |
| Do not compete | 0 | 245 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 411 | 0 | 21 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than LTSMin+red,
denote cases where Tapaal
computed more values than LTSMin+red,
![]() denote cases where Tapaal
computed less values than LTSMin+red,
denote cases where Tapaal
computed less values than LTSMin+red,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, LTSMin+red wins when points are above the diagonal.
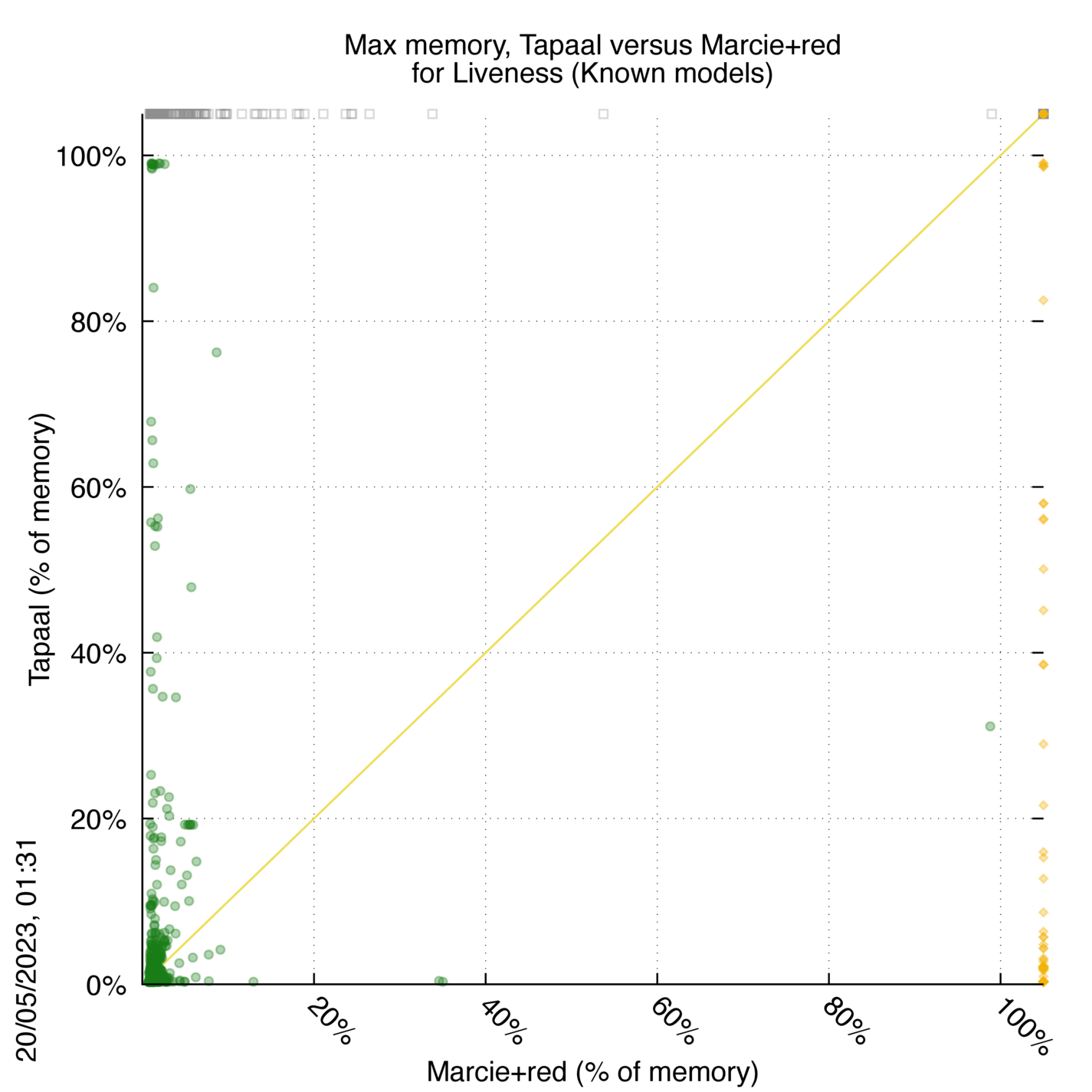
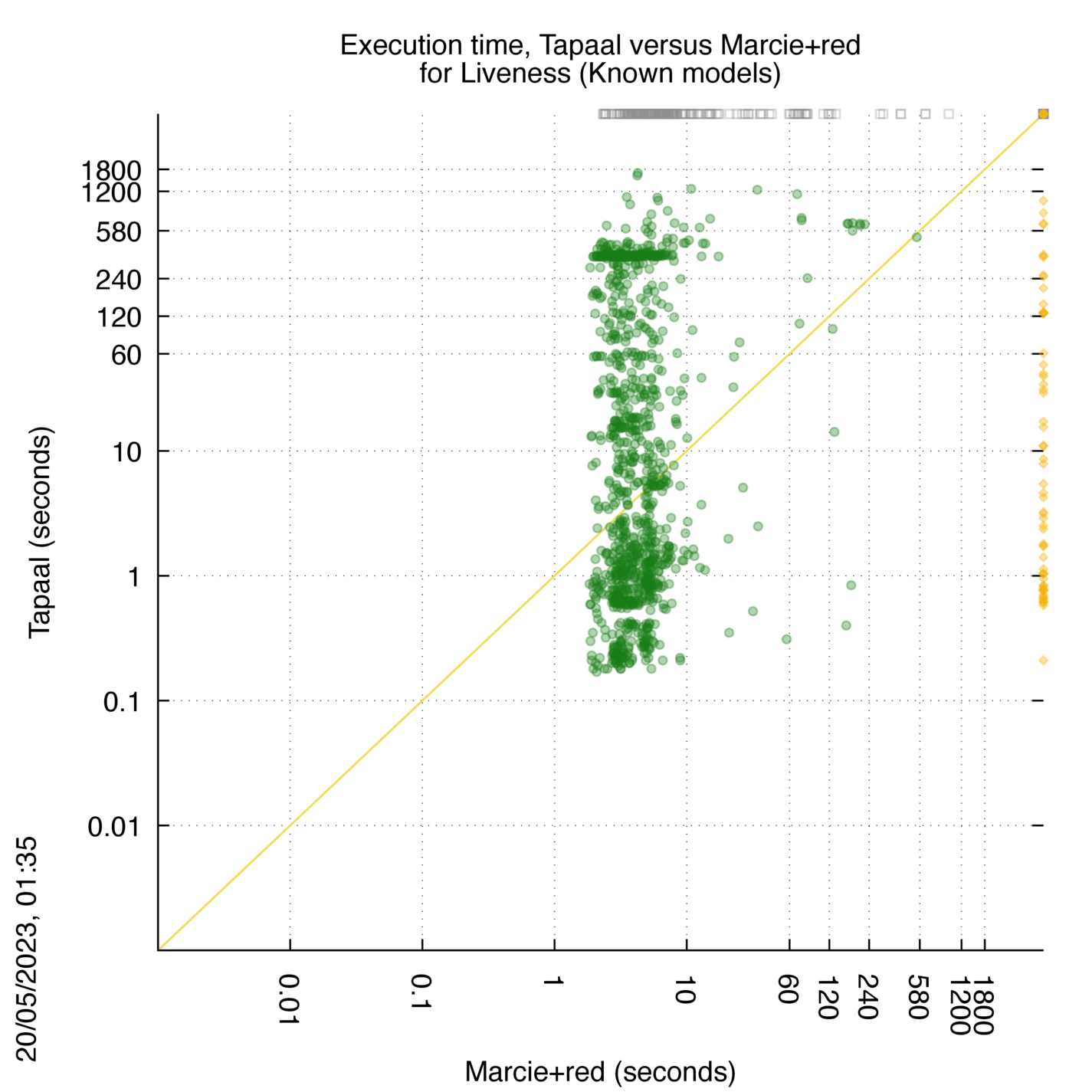
Tapaal versus Marcie+red
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for Marcie+red, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to Marcie+red are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | Marcie+red | Both tools | Tapaal | Marcie+red | ||
| All computed OK | 62 | 229 | 1123 | Smallest Memory Footprint | ||
| Tapaal = Marcie+red | — | — | 0 | Times tool wins | 879 | 535 |
| Tapaal > Marcie+red | — | — | 0 | Shortest Execution Time | ||
| Tapaal < Marcie+red | — | — | 0 | Times tool wins | 598 | 816 |
| Do not compete | 0 | 245 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 412 | 0 | 20 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than Marcie+red,
denote cases where Tapaal
computed more values than Marcie+red,
![]() denote cases where Tapaal
computed less values than Marcie+red,
denote cases where Tapaal
computed less values than Marcie+red,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, Marcie+red wins when points are above the diagonal.
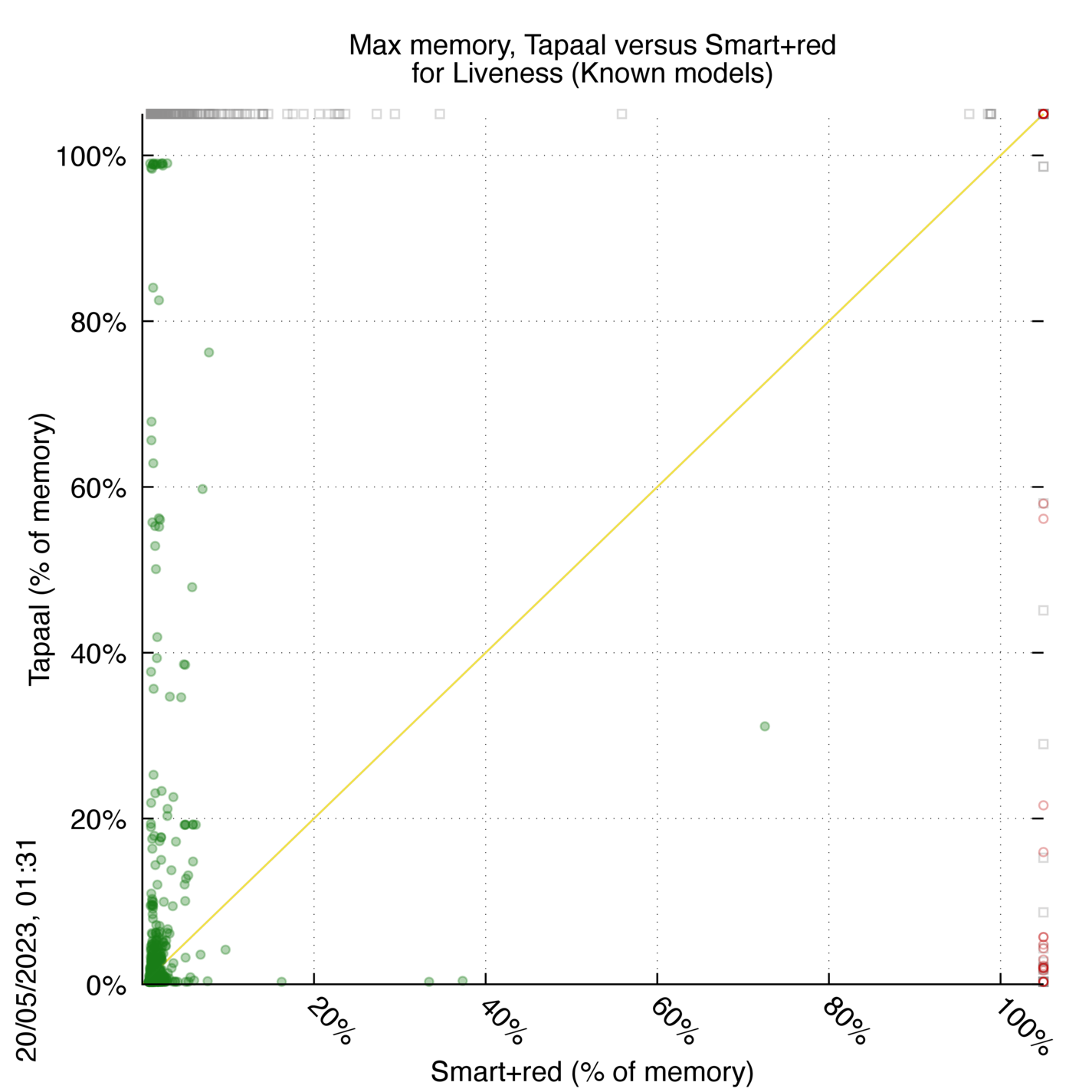
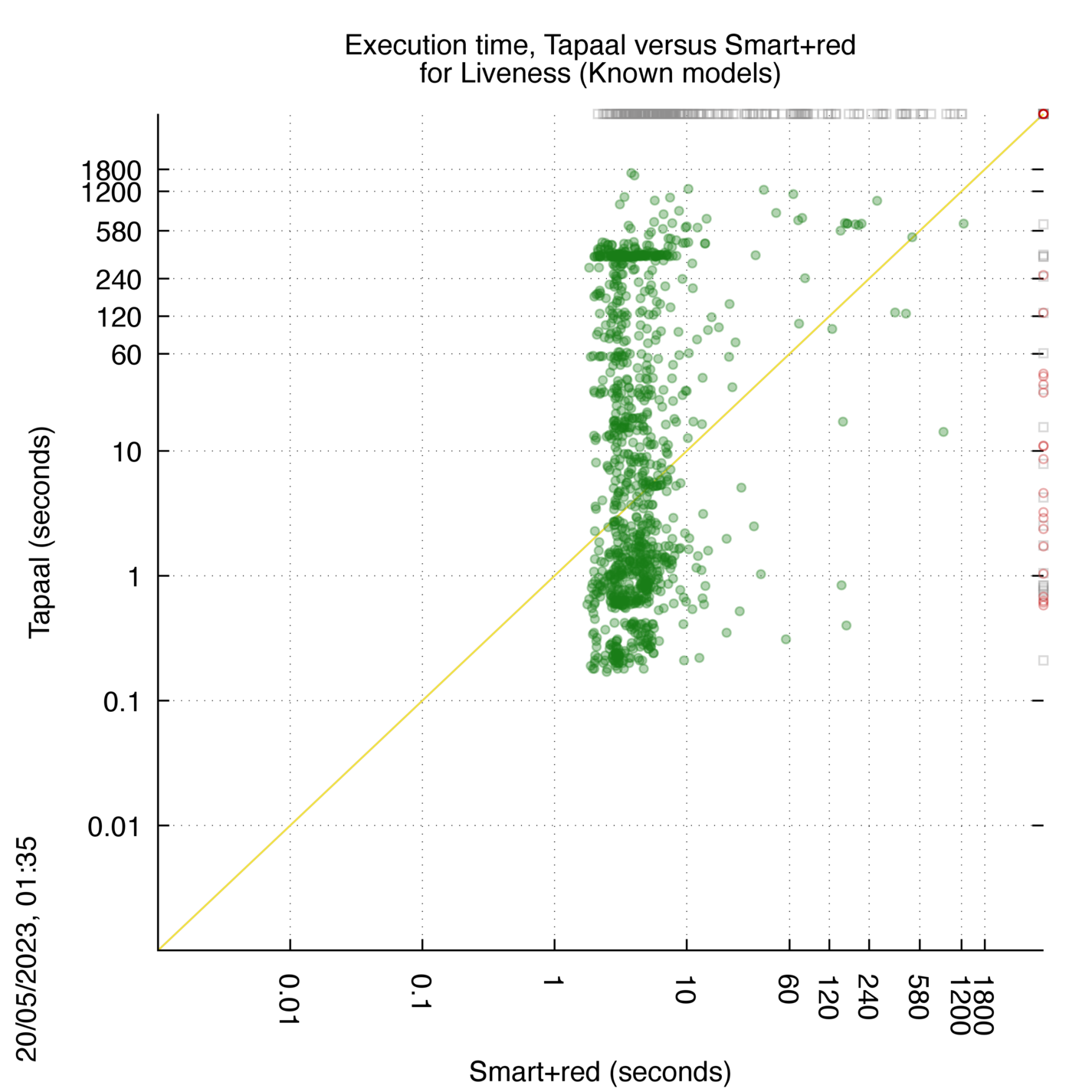
Tapaal versus Smart+red
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for Smart+red, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to Smart+red are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | Smart+red | Both tools | Tapaal | Smart+red | ||
| All computed OK | 40 | 269 | 1145 | Smallest Memory Footprint | ||
| Tapaal = Smart+red | — | — | 0 | Times tool wins | 869 | 585 |
| Tapaal > Smart+red | — | — | 0 | Shortest Execution Time | ||
| Tapaal < Smart+red | — | — | 0 | Times tool wins | 588 | 866 |
| Do not compete | 0 | 0 | 0 | |||
| Error detected | 0 | 43 | 0 | |||
| Cannot Compute + Time-out | 293 | 21 | 139 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than Smart+red,
denote cases where Tapaal
computed more values than Smart+red,
![]() denote cases where Tapaal
computed less values than Smart+red,
denote cases where Tapaal
computed less values than Smart+red,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, Smart+red wins when points are above the diagonal.
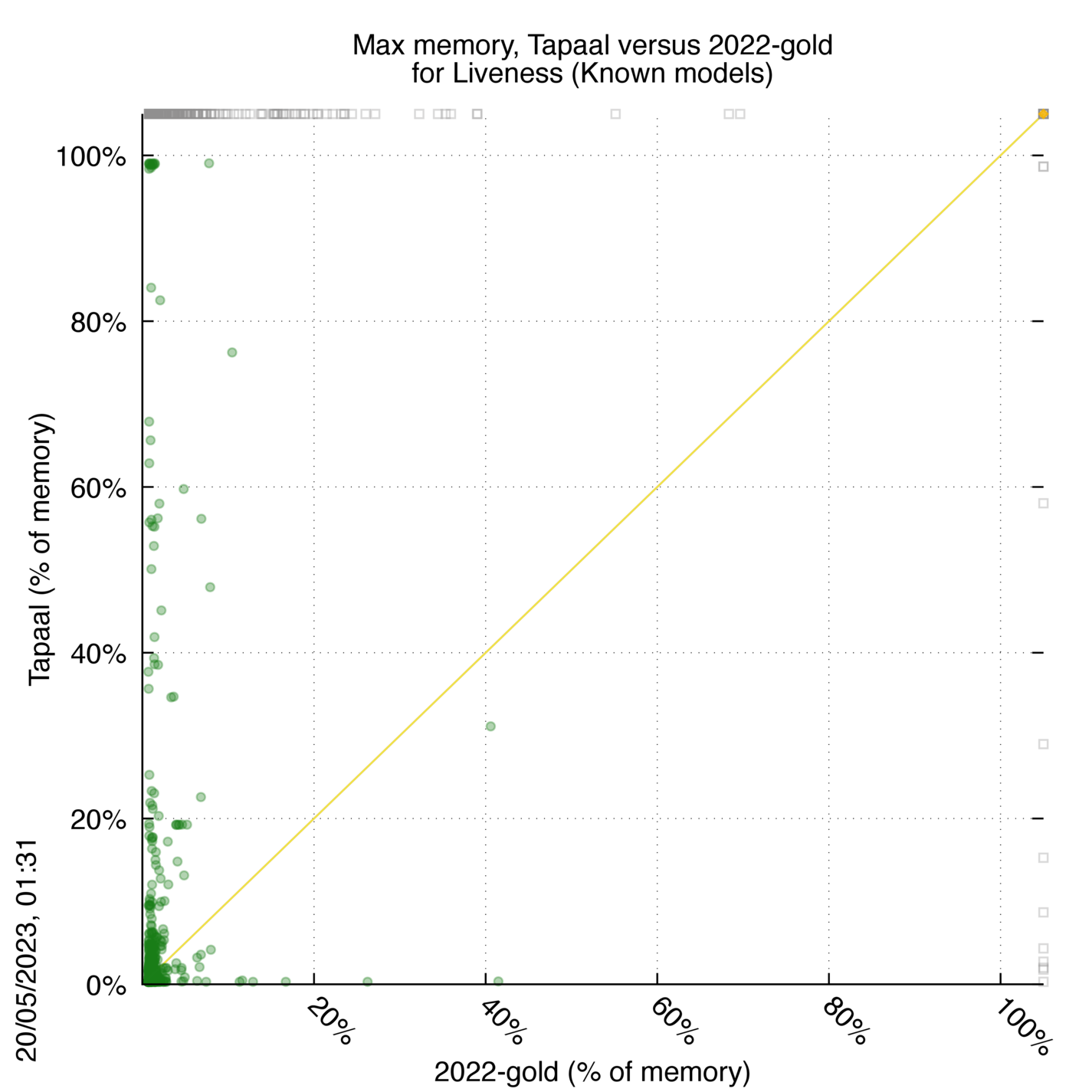
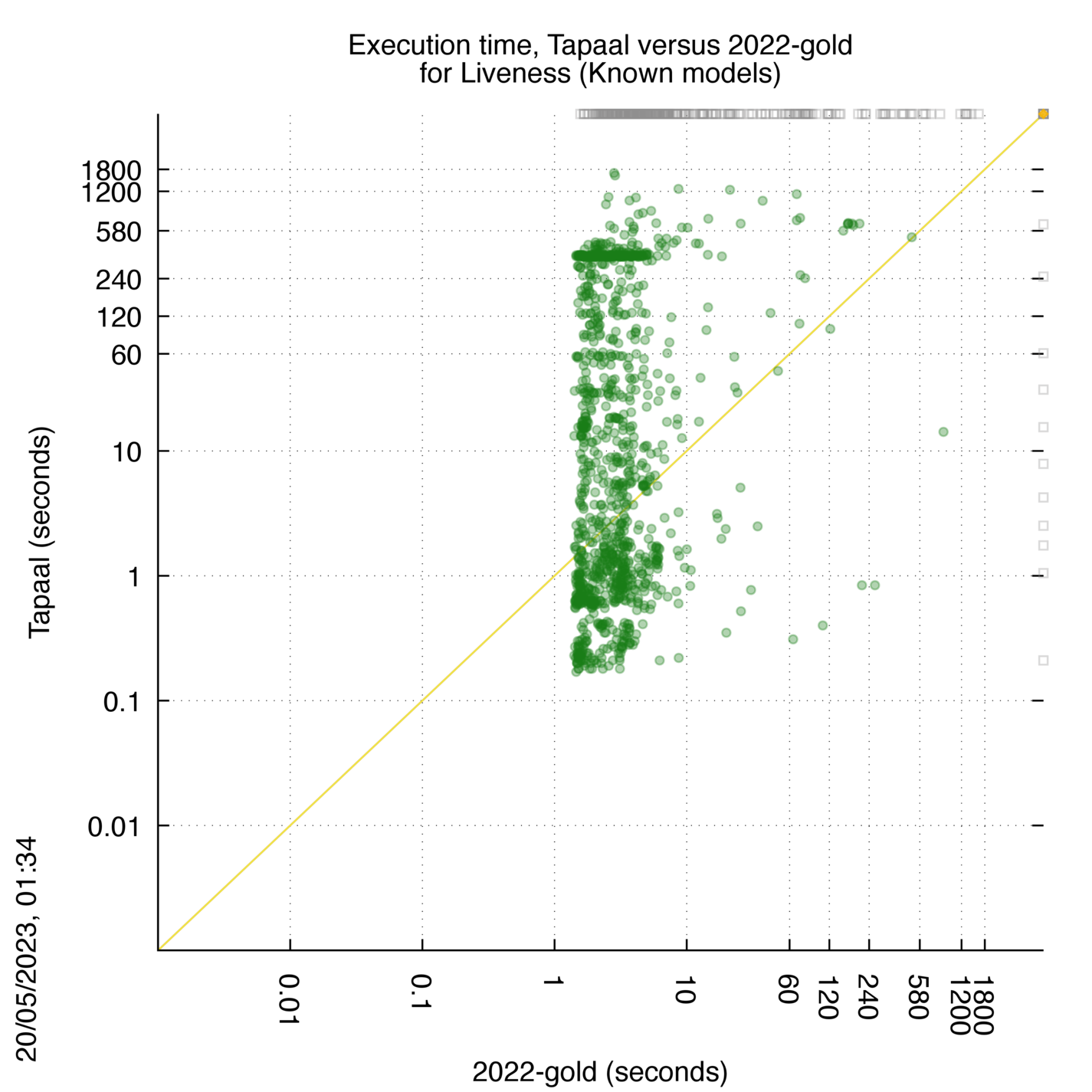
Tapaal versus 2022-gold
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for 2022-gold, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to 2022-gold are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | 2022-gold | Both tools | Tapaal | 2022-gold | ||
| All computed OK | 11 | 336 | 1174 | Smallest Memory Footprint | ||
| Tapaal = 2022-gold | — | — | 0 | Times tool wins | 830 | 691 |
| Tapaal > 2022-gold | — | — | 0 | Shortest Execution Time | ||
| Tapaal < 2022-gold | — | — | 0 | Times tool wins | 522 | 999 |
| Do not compete | 0 | 5 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 341 | 11 | 91 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than 2022-gold,
denote cases where Tapaal
computed more values than 2022-gold,
![]() denote cases where Tapaal
computed less values than 2022-gold,
denote cases where Tapaal
computed less values than 2022-gold,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, 2022-gold wins when points are above the diagonal.
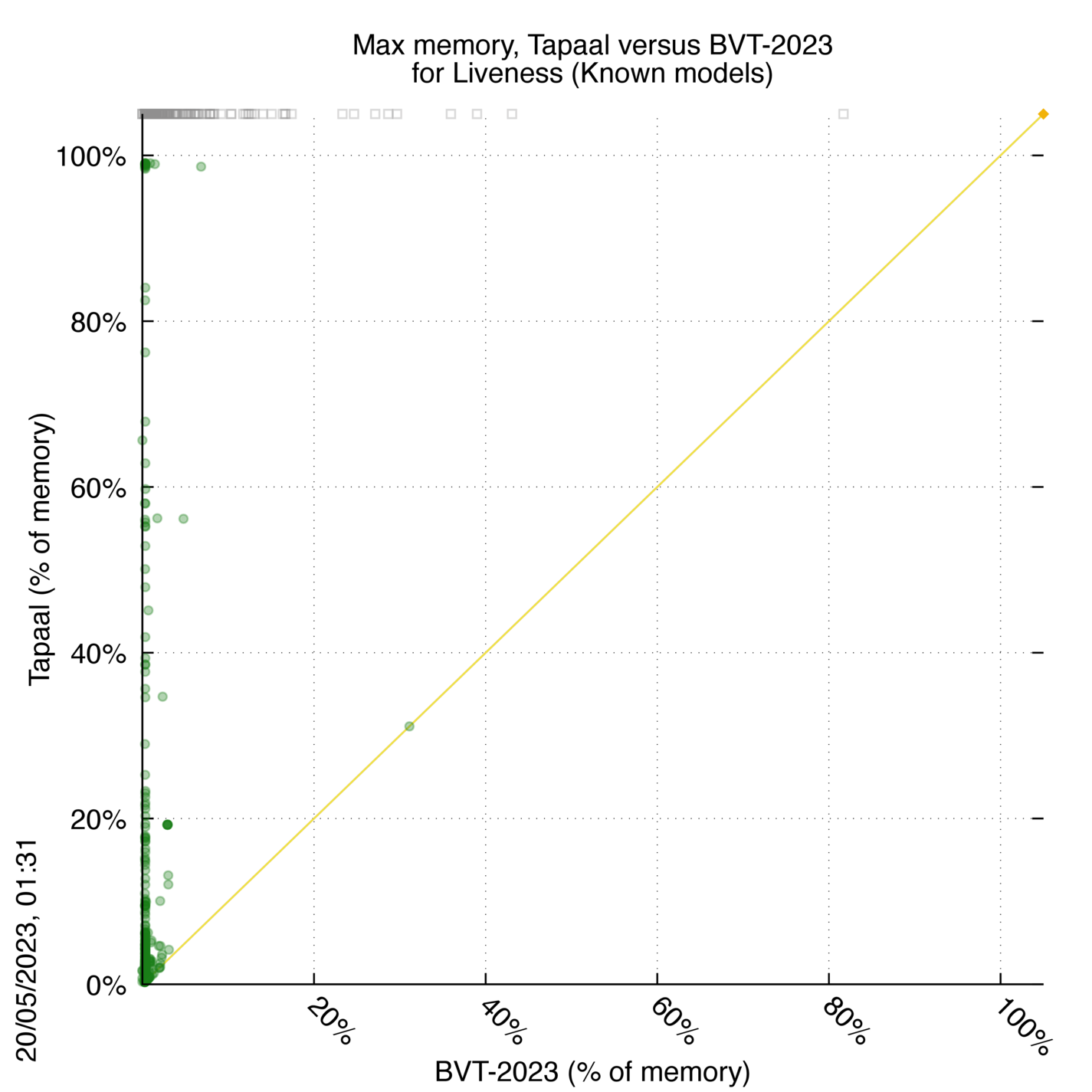
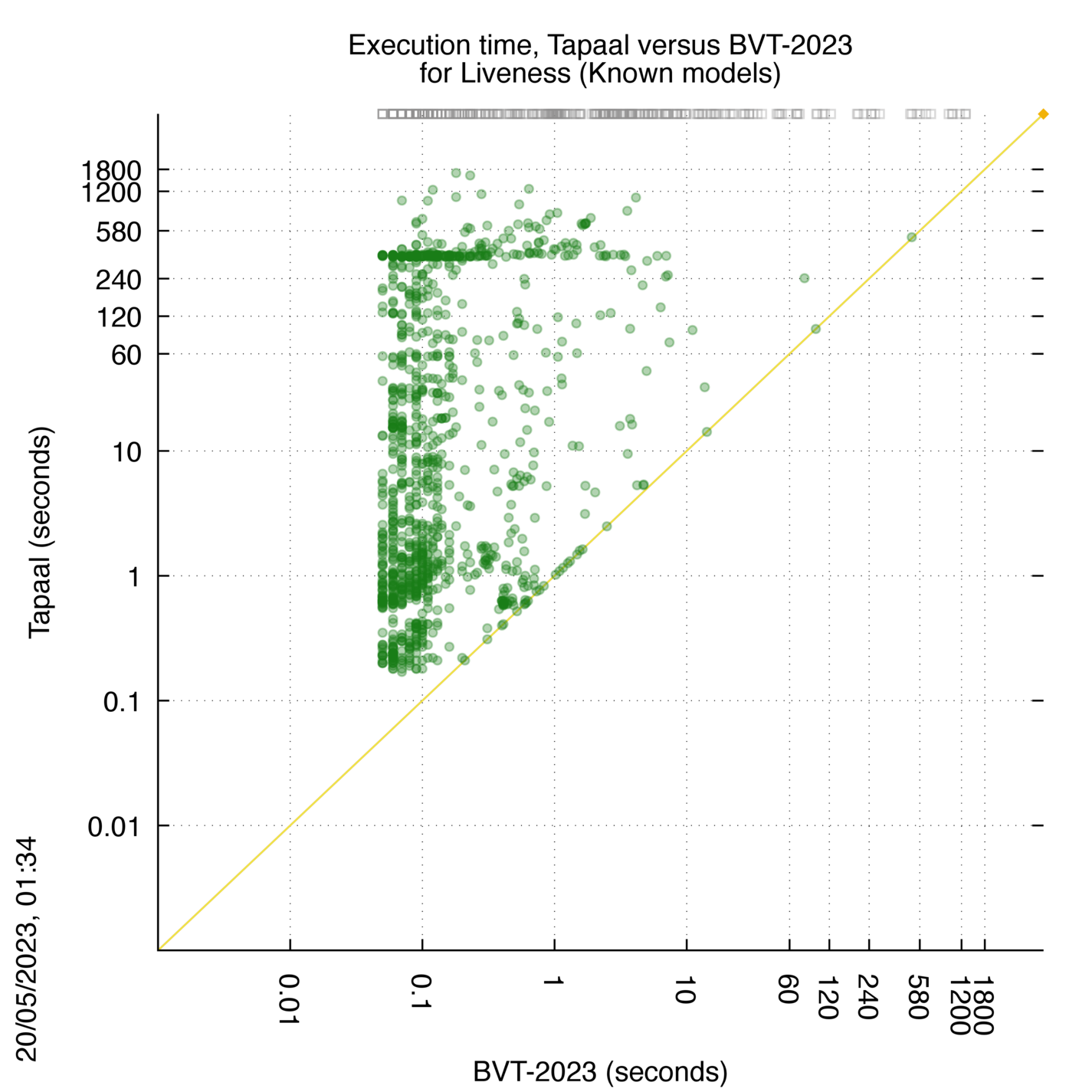
Tapaal versus BVT-2023
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for BVT-2023, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to BVT-2023 are shown (you may click on one graph to enlarge it).
Important: here, Tapaal is compared to BVT-2023. It is a good way to check how Tapaal compete in terms of resource consomption with the best tools (even virtual). When Tapaal is best, the corresponding plots are on the diagonal of the scatter plots chart.
| Statistics on the executions | ||||||
| Tapaal | BVT-2023 | Both tools | Tapaal | BVT-2023 | ||
| All computed OK | 0 | 366 | 1185 | Smallest Memory Footprint | ||
| Tapaal = BVT-2023 | — | — | 0 | Times tool wins | 0 | 1551 |
| Tapaal > BVT-2023 | — | — | 0 | Shortest Execution Time | ||
| Tapaal < BVT-2023 | — | — | 0 | Times tool wins | 0 | 1551 |
| Do not compete | 0 | 66 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 432 | 0 | 0 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than BVT-2023,
denote cases where Tapaal
computed more values than BVT-2023,
![]() denote cases where Tapaal
computed less values than BVT-2023,
denote cases where Tapaal
computed less values than BVT-2023,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, BVT-2023 wins when points are above the diagonal.
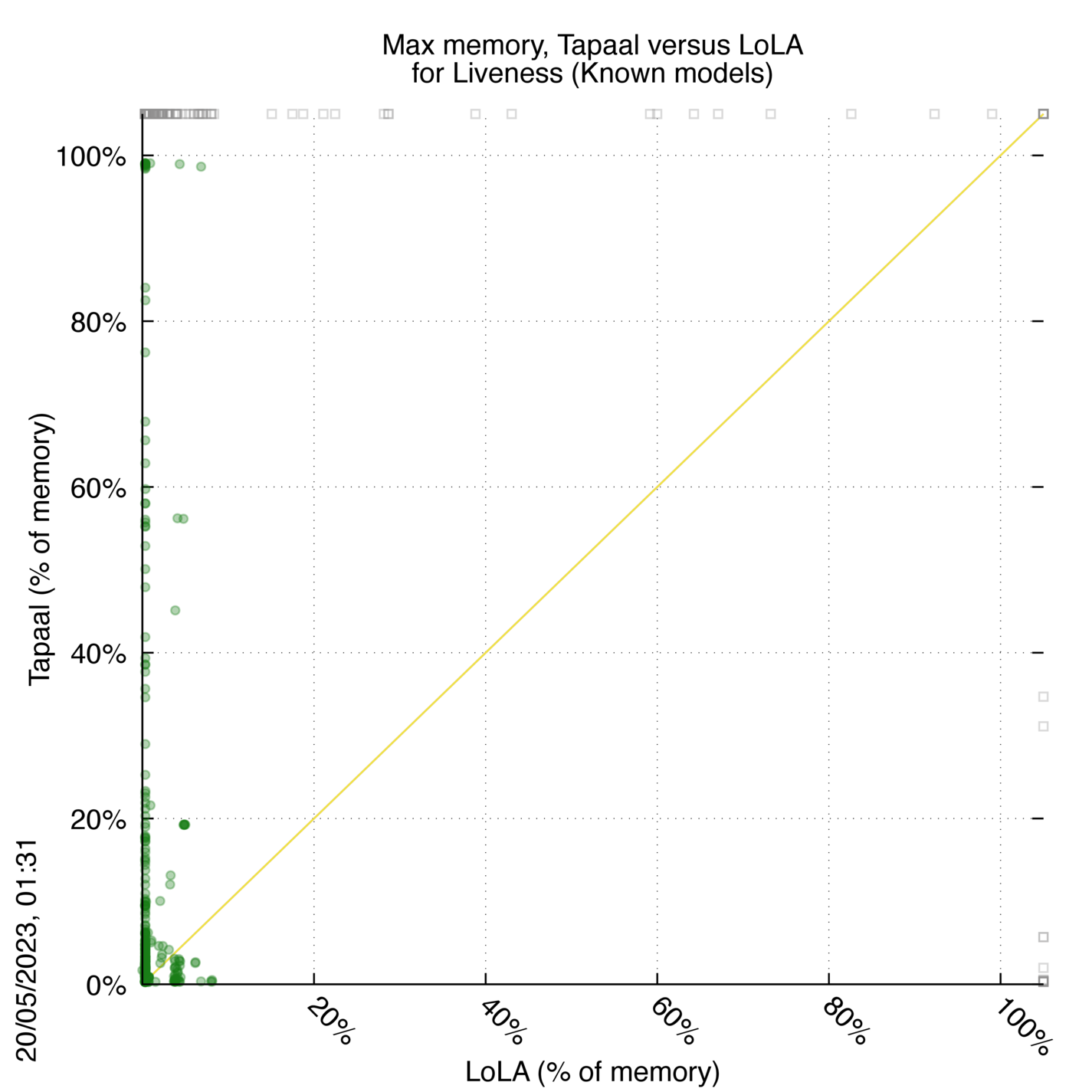
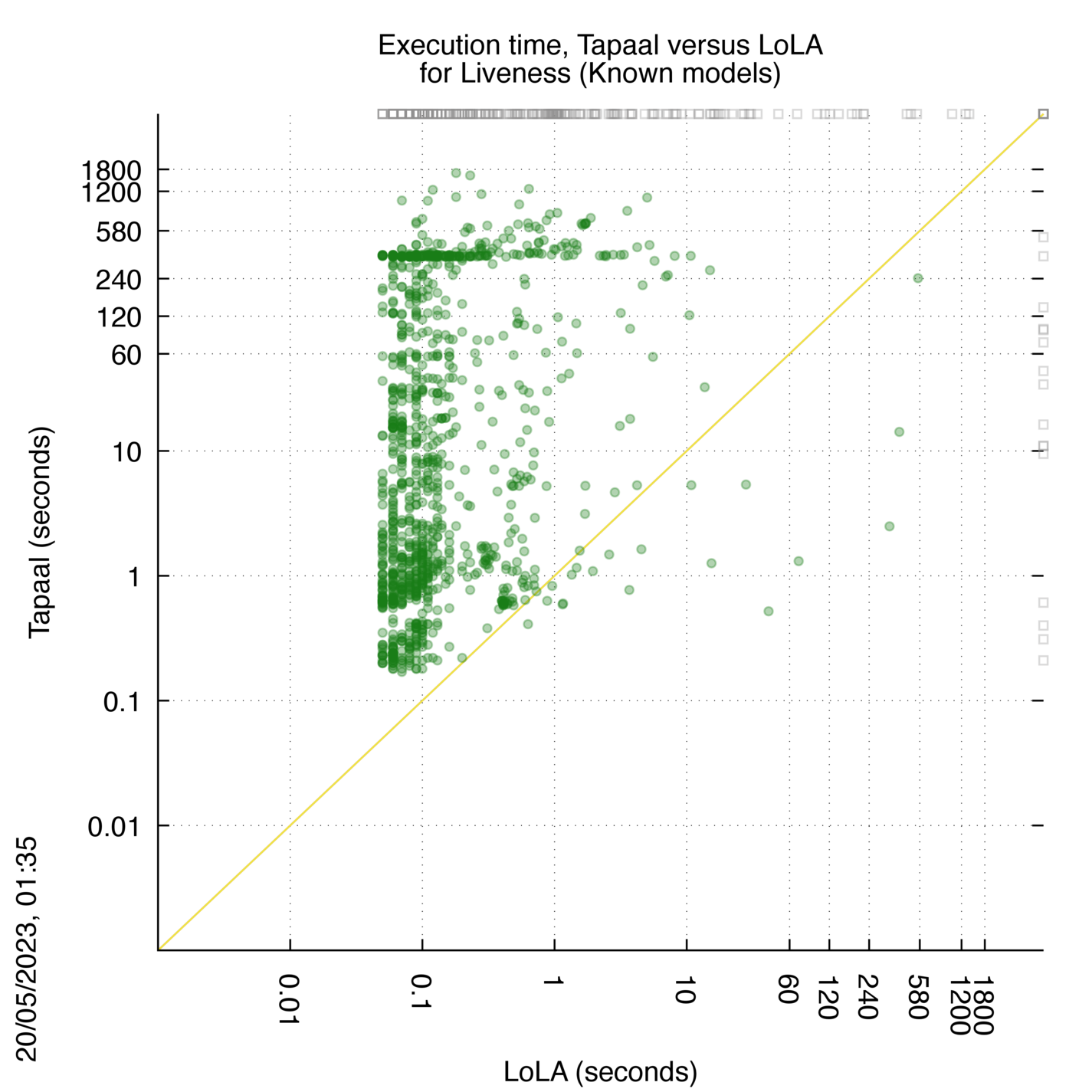
Tapaal versus LoLA
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for LoLA, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to LoLA are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | LoLA | Both tools | Tapaal | LoLA | ||
| All computed OK | 16 | 282 | 1169 | Smallest Memory Footprint | ||
| Tapaal = LoLA | — | — | 0 | Times tool wins | 518 | 949 |
| Tapaal > LoLA | — | — | 0 | Shortest Execution Time | ||
| Tapaal < LoLA | — | — | 0 | Times tool wins | 35 | 1432 |
| Do not compete | 0 | 0 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 282 | 16 | 150 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than LoLA,
denote cases where Tapaal
computed more values than LoLA,
![]() denote cases where Tapaal
computed less values than LoLA,
denote cases where Tapaal
computed less values than LoLA,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, LoLA wins when points are above the diagonal.
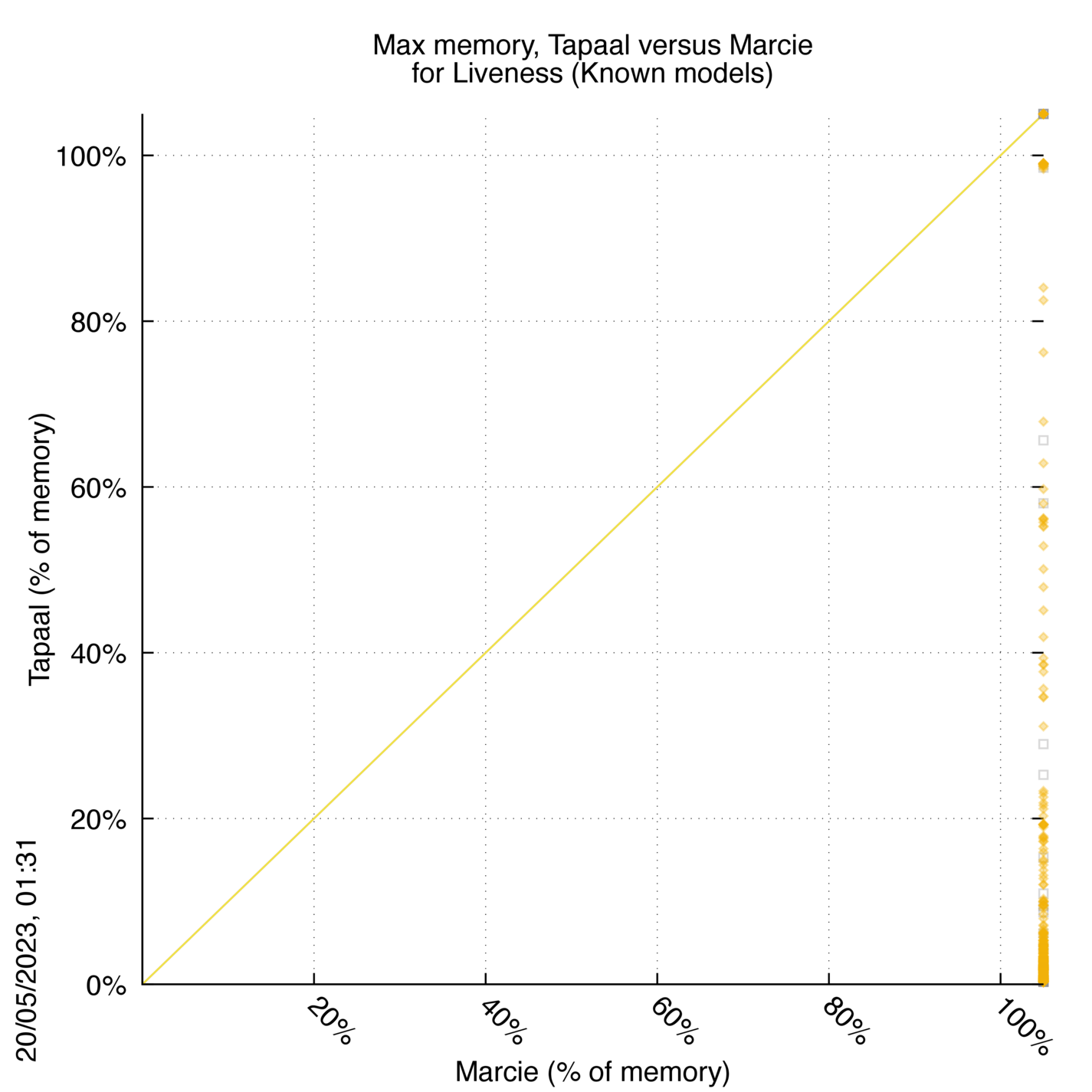
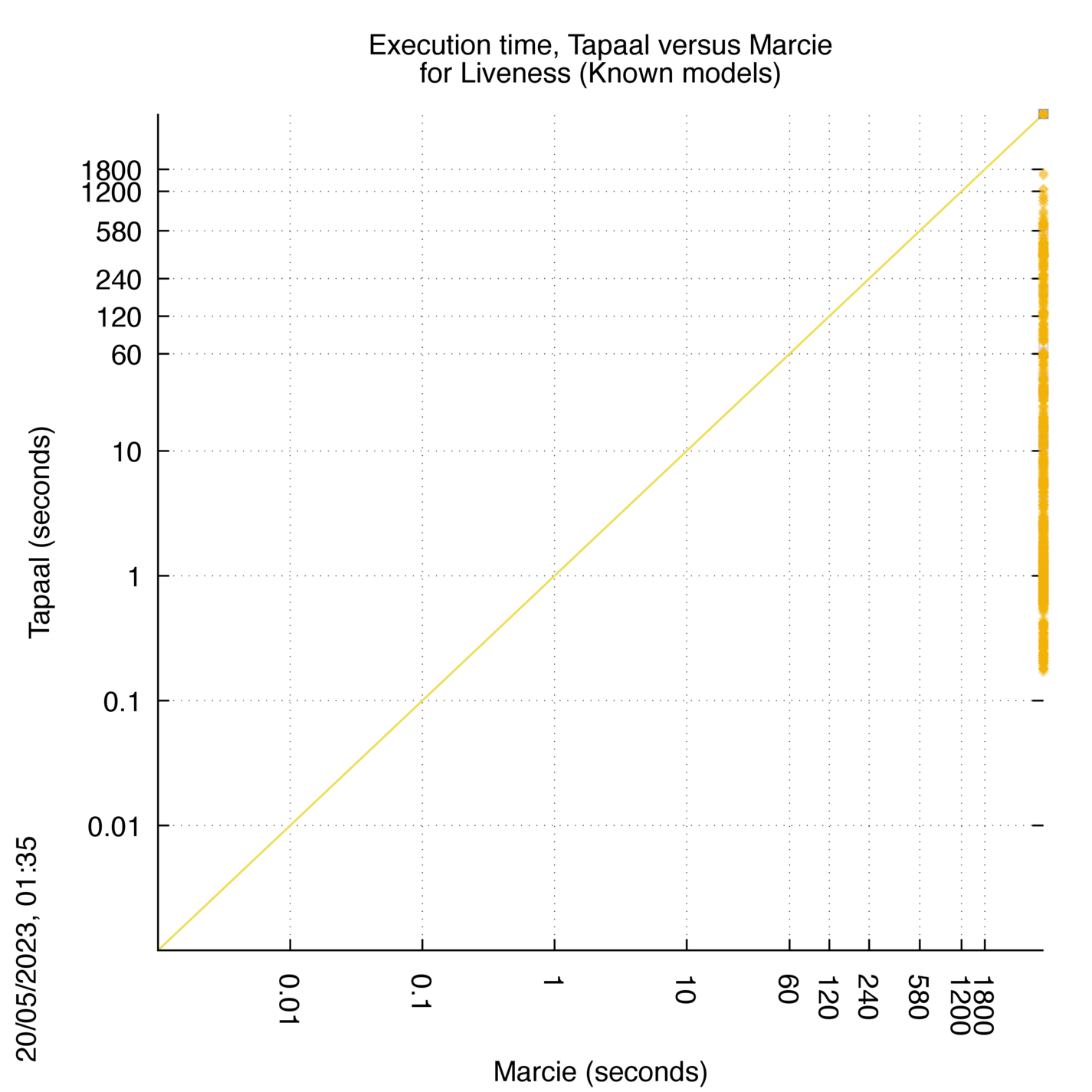
Tapaal versus Marcie
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for Marcie, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to Marcie are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | Marcie | Both tools | Tapaal | Marcie | ||
| All computed OK | 1185 | 0 | 0 | Smallest Memory Footprint | ||
| Tapaal = Marcie | — | — | 0 | Times tool wins | 1185 | 0 |
| Tapaal > Marcie | — | — | 0 | Shortest Execution Time | ||
| Tapaal < Marcie | — | — | 0 | Times tool wins | 1185 | 0 |
| Do not compete | 0 | 1581 | 0 | |||
| Error detected | 0 | 0 | 0 | |||
| Cannot Compute + Time-out | 427 | 31 | 5 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than Marcie,
denote cases where Tapaal
computed more values than Marcie,
![]() denote cases where Tapaal
computed less values than Marcie,
denote cases where Tapaal
computed less values than Marcie,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, Marcie wins when points are above the diagonal.
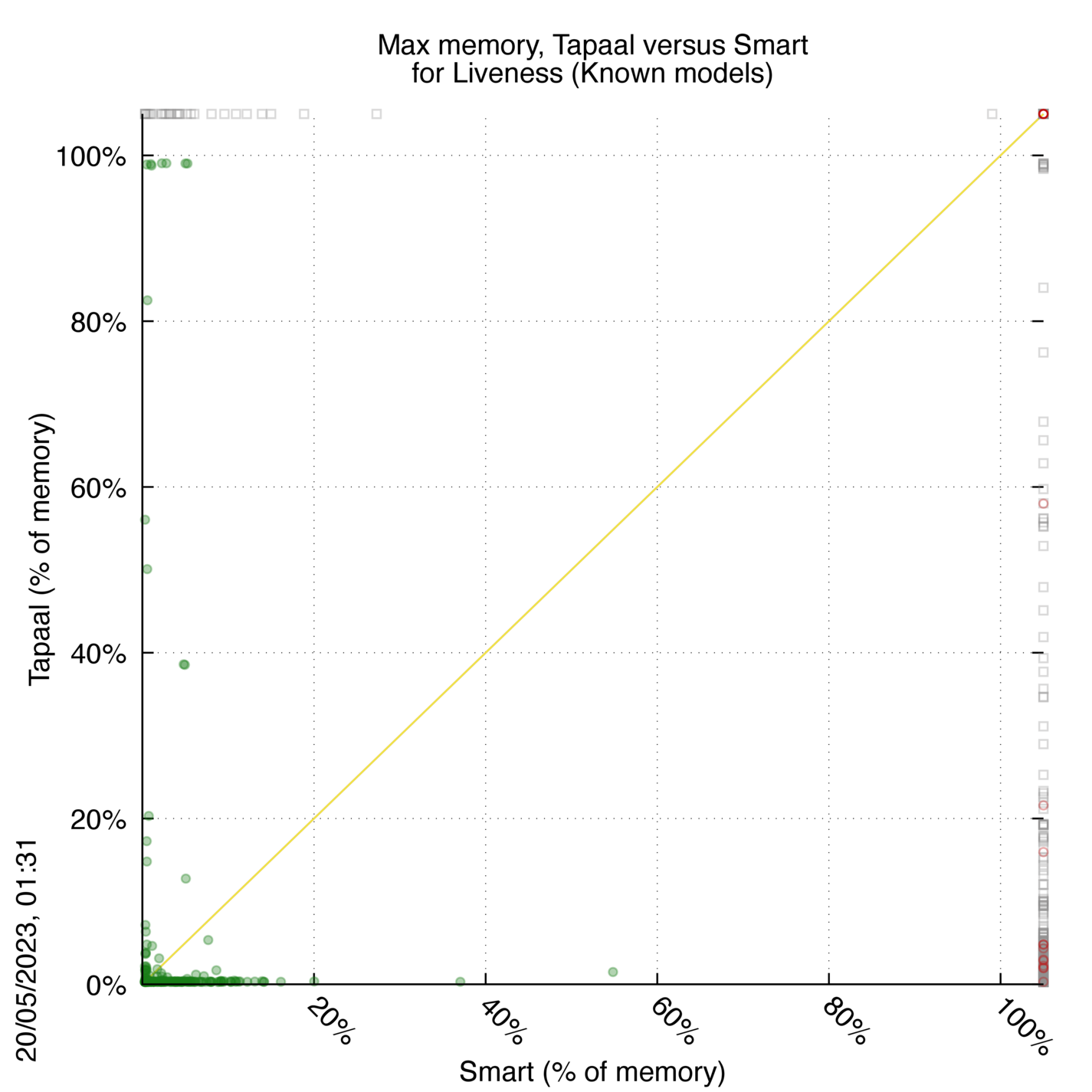
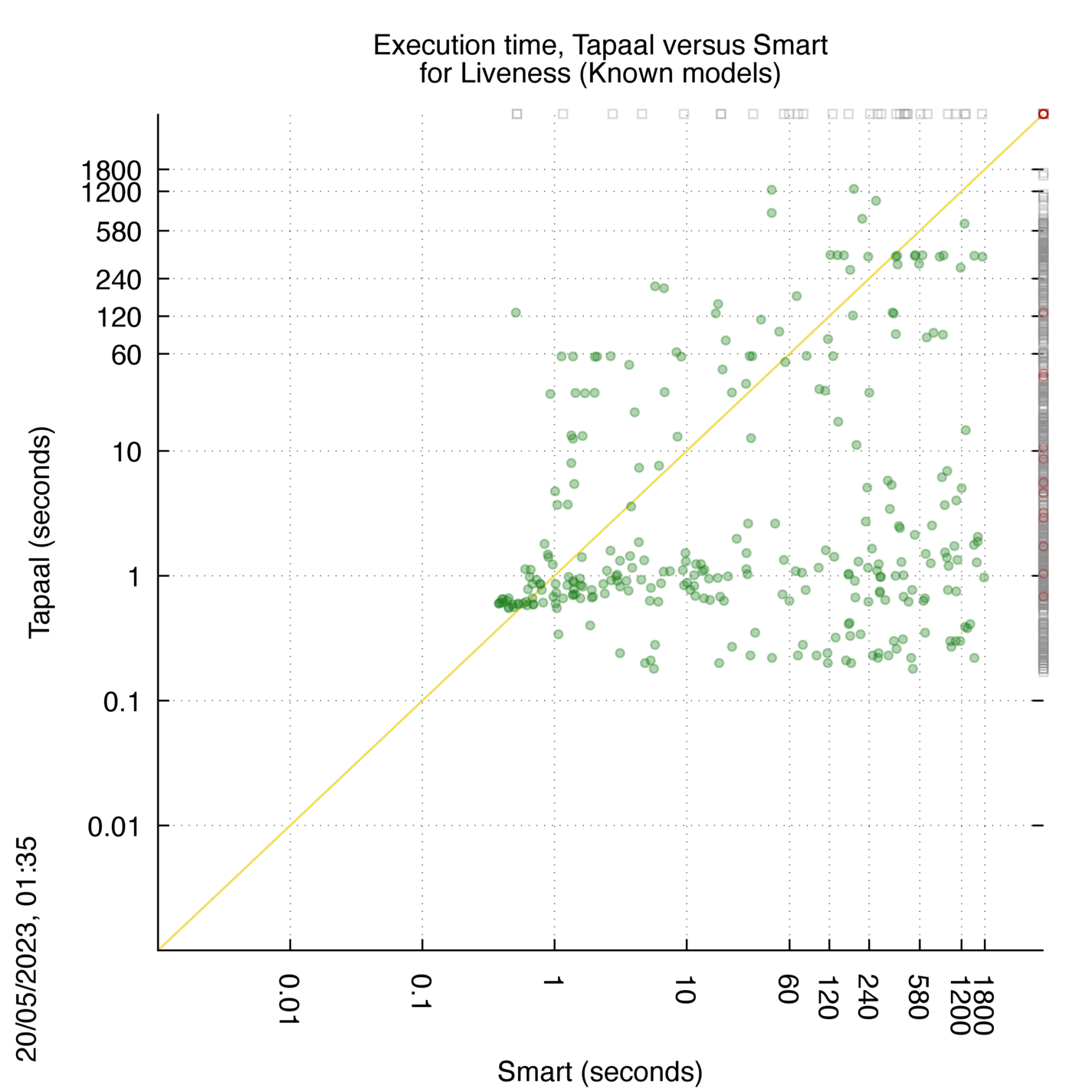
Tapaal versus Smart
Some statistics are displayed below, based on 3234 runs (1617 for Tapaal and 1617 for Smart, so there are 1617 plots on each of the two charts). Each execution was allowed 30 minutes and 16 GByte of memory. Then performance charts comparing Tapaal to Smart are shown (you may click on one graph to enlarge it).
| Statistics on the executions | ||||||
| Tapaal | Smart | Both tools | Tapaal | Smart | ||
| All computed OK | 897 | 31 | 288 | Smallest Memory Footprint | ||
| Tapaal = Smart | — | — | 0 | Times tool wins | 1128 | 88 |
| Tapaal > Smart | — | — | 0 | Shortest Execution Time | ||
| Tapaal < Smart | — | — | 0 | Times tool wins | 1108 | 108 |
| Do not compete | 0 | 0 | 0 | |||
| Error detected | 0 | 22 | 0 | |||
| Cannot Compute + Time-out | 41 | 885 | 391 | |||
On the chart below, ![]() denote cases where
the two tools did computed all results without error,
denote cases where
the two tools did computed all results without error,
![]() denote cases where the two tool did computed the
same number of values (but not al values in the examination),
denote cases where the two tool did computed the
same number of values (but not al values in the examination),
![]() denote cases where Tapaal
computed more values than Smart,
denote cases where Tapaal
computed more values than Smart,
![]() denote cases where Tapaal
computed less values than Smart,
denote cases where Tapaal
computed less values than Smart,
![]() denote the cases where at least one tool did not competed,
denote the cases where at least one tool did not competed,
![]() denote the cases where at least one
tool computed a bad value and
denote the cases where at least one
tool computed a bad value and ![]() denote the cases where at least one tool stated it could not compute a result or timed-out.
denote the cases where at least one tool stated it could not compute a result or timed-out.
Tapaal wins when points are below the diagonal, Smart wins when points are above the diagonal.