

1. Introduction
This page summarizes the results for the 2021 edition of the Model Checking Contest (MCC’2021). This page is divided in three sections:
- First, we list the qualified tools for the MCC'2021,
- Then, we provide some informations about the experimental conditions of the MCC'2021,
- Then, we present an access to details about results,
- Then, we provide the list of winners of the MCC'2021,
- Finally, we provide an attempt to evaluate tool reliability based on the comparison of the results provided in the contest.
IMPORTANT:all these documents can be reused in scientific material and papers but must respect the Creative Common license CC-BY-NC-SA.
2. List of Qualified Tools in 2021
Ten tools where submitted this year. They all successfully went through a qualification process requiring about 1500 runs (each tool had to answer each examination for the first instance of each «known» model).
Data about these tools are summarized in the table below. For any tool, you can download the disk image that was provided with all its data. You may use these to reproduce measures locally and perform comparison with your own tool on the same benchmark. Please note that one tool (with two variants) was out of competition this year: this was agreed between the tool developer and the organizers and is part of an experiment with precomputed deep-learning.
IMPORTANT: all tool developers agreed to provide the original image disk embedding the tool they submitted his year (see links in the table below). You may operate these tools on your own. To do so, you need the second disk image (mounted by the other one) that contains all models for 2021 together with the produced formulas. This image is mounted with the default configuration, as well as in he default disk image provided in the tool submission kit (see here).
IMPORTANT: You also have access to the archive containing all models and the corresponding formulas for 2021 here.
| Summary of the Participating Tools | ||||||
| Tool name | Supported Petri nets |
Representative Author | Origin | Type of execution | Link to the submitted disk image | Reported Techniques (all examinations) |
|---|---|---|---|---|---|---|
| enPAC | P/T and colored | Cong He & Shuo Li | Tongji University, Shanghai (China) | Sequential Processing |  |
ABSTRACTIONS EXPLICIT SEQUENTIAL_PROCESSING STATE_COMPRESSION |
| GreatSPN-Meddly | P/T and colored | Elvio Amparore | Univ. Torino (Italy) | Collateral Processing | |
DECISION_DIAGRAMS PARALLEL_PROCESSING TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN |
| ITS-Tools | P/T and colored | Yann Thierry-Mieg | Sorbonne Université | Collateral Processing | |
BESTFIRST_WALK COLLATERAL_PROCESSING CPN_APPROX DEADLOCK_TEST DECISION_DIAGRAMS EXHAUSTIVE_WALK EXPLICIT INITIAL_STATE INVARIANTS K_INDUCTION LTSMIN MARKED_SUFFIX_TEST OVER_APPROXIMATION PARIKH_WALK PARTIAL_ORDER PROBABILISTIC_WALK QUASILIVENESS_TEST RANDOM_WALK SAT_SMT SCC_TEST SIPHON_TEST SKELETON_TEST STRUCTURAL STRUCTURAL_REDUCTION STUTTER_TEST TOPOLOGICAL TRIVIAL_UNMARKED_SCC_TEST USE_NUPN |
| LoLA | P/T and colored | Karsten Wolf | Rostock University | Collateral Processing | |
COLLATERAL_PROCESSING EXPLICIT SEQUENTIAL_PROCESSING STATE_COMPRESSION STUBBORN_SETS TOPOLOGICAL UNFOLDING_TO_PT UNFOLDING_TO_PTFORMULA USE_NUPN |
| smpt | P/T and colored | Nicolas Amat | LAAS/CNRS/Université de Toulouse | Collateral Processing | |
COLLATERAL_PROCESSING CONSTRAINT_PROGRAMMING IMPLICIT NET_UNFOLDING SAT-SMT STRUCTURAL_REDUCTION UNFOLDING_TO_PT |
| Tapaal | P/T and colored | Jiri Srba | Aalborg Universitet | Collateral Processing | |
COLLATERAL_PROCESSING CPN_APPROX CTL_CZERO EXPLICIT LP_APPROX NDFS QUERY_REDUCTION SAT_SMT SIPHON_TRAP STATE_COMPRESSION STRUCTURAL_REDUCTION STUBBORN_SETS TARJAN TOPOLOGICAL TRACE_ABSTRACTION_REFINEMENT UNFOLDING_TO_PT WEAK_SKIP |
| TINA.tedd | P/T and colored | Bernard Berthomieu & Silvano Dal Zilio | LAAS/CNRS/Université de Toulouse | Sequential Processing | |
DECISION_DIAGRAMS IMPLICIT LINEAR_EQUATIONS SEQUENTIAL_PROCESSING STRUCTURAL_REDUCTION TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN |
The table below lists the techniques reported per examination (and for all the tool variants when applicable).
| Techniques Reported by the Participating Tools (per examination) | ||||||
| Tool name | StateSpace | GlobalProperties | UpperBounds | Reachability | CTL | LTL |
|---|---|---|---|---|---|---|
| enPAC | — | — | — | — | — | ABSTRACTIONS EXPLICIT SEQUENTIAL_PROCESSING STATE_COMPRESSION |
| GreatSPN-Meddly | DECISION_DIAGRAMS PARALLEL_PROCESSING TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | DECISION_DIAGRAMS PARALLEL_PROCESSING TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | DECISION_DIAGRAMS PARALLEL_PROCESSING TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | DECISION_DIAGRAMS PARALLEL_PROCESSING TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | DECISION_DIAGRAMS PARALLEL_PROCESSING TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | DECISION_DIAGRAMS PARALLEL_PROCESSING TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN |
| ITS-Tools | DECISION_DIAGRAMS TOPOLOGICAL USE_NUPN | BESTFIRST_WALK COLLATERAL_PROCESSING CPN_APPROX DEADLOCK_TEST DECISION_DIAGRAMS EXHAUSTIVE_WALK EXPLICIT INITIAL_STATE INVARIANTS LTSMIN MARKED_SUFFIX_TEST PARIKH_WALK PARTIAL_ORDER PROBABILISTIC_WALK QUASILIVENESS_TEST RANDOM_WALK SAT_SMT SCC_TEST SIPHON_TEST SKELETON_TEST STRUCTURAL STRUCTURAL_REDUCTION TOPOLOGICAL TRIVIAL_UNMARKED_SCC_TEST USE_NUPN | BESTFIRST_WALK CPN_APPROX DECISION_DIAGRAMS INITIAL_STATE PARIKH_WALK RANDOM_WALK SAT_SMT TOPOLOGICAL USE_NUPN | BESTFIRST_WALK COLLATERAL_PROCESSING DECISION_DIAGRAMS EXHAUSTIVE_WALK EXPLICIT INITIAL_STATE K_INDUCTION LTSMIN PARIKH_WALK PARTIAL_ORDER PROBABILISTIC_WALK RANDOM_WALK SAT_SMT STRUCTURAL_REDUCTION TOPOLOGICAL USE_NUPN | BESTFIRST_WALK DECISION_DIAGRAMS EXHAUSTIVE_WALK INITIAL_STATE OVER_APPROXIMATION PARIKH_WALK PROBABILISTIC_WALK RANDOM_WALK SAT_SMT STRUCTURAL_REDUCTION TOPOLOGICAL USE_NUPN | DECISION_DIAGRAMS EXPLICIT INITIAL_STATE LTSMIN PARTIAL_ORDER SAT_SMT STRUCTURAL STUTTER_TEST TOPOLOGICAL USE_NUPN |
| LoLA | — | COLLATFOLDING_TO_PT USE_NUPN | COLLATERAL_PROCESSING EXPLICIT STATE_COMPRESSION STUBBORN_SETS TOPOLOGICAL UNFOLDING_TO_PT UNFOLDING_TO_PTFORMULA USE_NUPN USE_NUPN | COLLATERAL_PROCESSING EXPLICIT STATE_COMPRESSION STUBBORN_SETS TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | COLLATERAL_PROCESSING EXPLICIT STATE_COMPRESSION STUBBORN_SETS TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | COLLATERAL_PROCESSING EXPLICIT STATE_COMPRESSION STUBBORN_SETS TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN |
| smpt | — | — | — | COLLATERAL_PROCESSING CONSTRAINT_PROGRAMMING IMPLICIT NET_UNFOLDING STRUCTURAL_REDUCTION UNFOLDING_TO_PT | — | — |
| Tapaal | EXPLICIT STATE_COMPRESSION | COLLATERAL_PROCESSING CTL_CZERO EXPLICIT LP_APPROX QUERY_REDUCTION SAT_SMT SIPHON_TRAP STATE_COMPRESSION STRUCTURAL_REDUCTION STUBBORN_SETS TOPOLOGICAL TRACE_ABSTRACTION_REFINEMENT UNFOLDING_TO_PT | COLLATERAL_PROCESSING EXPLICIT QUERY_REDUCTION SAT_SMT STATE_COMPRESSION STRUCTURAL_REDUCTION STUBBORN_SETS TRACE_ABSTRACTION_REFINEMENT | COLLATERAL_PROCESSING CPN_APPROX EXPLICIT LP_APPROX QUERY_REDUCTION SAT_SMT STATE_COMPRESSION STRUCTURAL_REDUCTION STUBBORN_SETS TRACE_ABSTRACTION_REFINEMENT UNFOLDING_TO_PT | COLLATERAL_PROCESSING CPN_APPROX CTL_CZERO EXPLICIT LP_APPROX QUERY_REDUCTION SAT_SMT STATE_COMPRESSION STRUCTURAL_REDUCTION STUBBORN_SETS TRACE_ABSTRACTION_REFINEMENT UNFOLDING_TO_PT | COLLATERAL_PROCESSING EXPLICIT LP_APPROX NDFS QUERY_REDUCTION SAT_SMT STATE_COMPRESSION STRUCTURAL_REDUCTION STUBBORN_SETS TARJAN UNFOLDING_TO_PT WEAK_SKIP |
| TINA.tedd | DECISION_DIAGRAMS IMPLICIT LINEAR_EQUATIONS SEQUENTIAL_PROCESSING STRUCTURAL_REDUCTION TOPOLOGICAL UNFOLDING_TO_PT USE_NUPN | — | — | — | — | — |
3. Experimental Conditions of the MCC'2021
Each tool was submitted to 18 343 executions in various conditions (1 411 model/instances and 13 examinations per model/instance) for which it could report: DNC (do not compete), CC (cannot compute) or the result of the query. These executions were handled by BenchKit, that was developed in the context of the MCC for massive testing of software. Then, from the raw data provided by BenchKit, some post-analysis scripts consolidated these and computed a ranking.
16 GB of memory were allocated to each virtual machine (both parallel and sequential tools) and a confinement of one hour was considered (execution aborted after one hour). So, a total of 146 744 runs (execution of one examination by the virtual machine) generated 30 GB of raw data (essentially log files and CSV of sampled data).
The table below shows some data about the involved machines and their contribution to the computation of these results. This year, we affected only physical cores to the virtual machines (discarding logical cores obtained from hyper-threading) so the balance between the various machine we used is quite different from he one of past years.
| Involved Machines and Execution of the Benchmarks | |||||||
| Tajo | Octoginta-2 | tall | Small | Total | |||
|---|---|---|---|---|---|---|---|
| Physical Cores | 96 @ 2.40GHz | 80 @ 2.4GHz | 12×32 @ 2.1GHz | 9×12 @ 2.4GHz | — | ||
| Memory (GB) | 1536 | 1536 | 12×384 | 9×64 | — | ||
| Used Cores (sequential tools) | 95, 95 VM in // |
79, 79 VM in // |
12×31, 12×31 VM in // |
9×3, 9×3 VM in // |
— | ||
| Used Cores (parallel tools) | 92 (4 per VM), 23 VM in // |
76 (4 per VM), 19 VM in // |
11×28 (4 per VM), 11×7 VM in // |
9×8 (4 per VM), 9×2 VM in // |
— | ||
| Number of runs | 18 200 | 15 184 | 95 472 | 17 888 | 146 744 | ||
| Total CPU consumed | 309d, 11h, 55m, 25s | 367d, 11h, 38mn 13s | 1592d, 23h, 10m, 43s | 286d, 12h, 50m, 46s | 2556d, 11h, 35m, 8s | ||
| Total CPU | About 7 years and 1 day | — | |||||
| Time spent to complete benchmarks | about 25 days | — | |||||
| Estimated boot time of VMs + management (overhead) |
8d, 12h (Included in total CPU) so ≅ 3 ‰ overhead | — | |||||
We are pleased to thanks those who helped in the execution of tools:
- Tajo was made available by colleagues at Rostock University,
- Octoginta-2 were made available by colleagues at Université Paris Nanterre and was partially funded by LIP6,
- Tall (we used 12 nodes) and small (we used 9 nodes) are clusters at LIP6 Sorbonne Université.
4. The Results of the MCC’2021
This First table below presents detailed results about the MCC'2021.
| Details about the Examinations in the MCC'g (part I): Details about Results and Scoring + Model Performance Charts |
|||
| Details about Results and Scoring |
Model Performance Charts |
Tool Resource consumption |
|
|---|---|---|---|
| StateSpace | |||
| ReachabilityDeadlock (GlobalProperties) | |||
| QuasiLiveness (GlobalProperties) | |||
| StableMarking (GlobalProperties) | |||
| Liveness (GlobalProperties) | |||
| OneSafe (GlobalProperties) | |||
| UpperBounds | |||
| ReachabilityCardinality | |||
| ReachabilityFireability | |||
| CTLCardinality | |||
| CTLFireability | |||
| LTLCardinality | |||
| LTLFireability | |||
This Second table below presents some performance analysis related to tools during the MCC'2021.
| Details about the examinations in the MCC'2021 (part II)Tool Performance Charts | ||||
| All models |
«Surprise» models only |
«Known» models only |
||
|---|---|---|---|---|
| enPAC | ||||
| GreatSPN-Meddly | ||||
| ITS-Tools | LoLA | |||
| smart | ||||
| Tapaal | ||||
| TINA.tedd | ||||
| 2019-Gold | ||||
You can download the full archive (2.8 GB compressed and 30 GB uncompressed) of the 127 816 runs processed to compute the results of the MCC'2021. This archive contains execution traces, execution logs and sampling, as well as a large CSV files that summarizes all the executions and gnuplot scripts and data to generate the charts produced in the web site (please have a look on the READ_ME.txt file). Yo may get separately the two mostly interesting CSV files:
- GlobalSummary.csv that summarizes all results from all runs in the contest (24 MB when expanded),
- raw-result-analysis.csv that contains the same data as the previous one but enriched with scoring information and the expected results (computed as a majority of tools pondered by their confidence rate, 29 MB when expanded).
Note that from the two CSV file, you can identify the unique run identifier that allows you to find the traces and any information in the archive (they are also available on the web site when the too did participated).
5. The Winners for the MCC'2021
This section presents the results for the main examinations that are:
- State Space generation,
- UpperBounds computation,
- GlobalProperties computation (ReachabilityDeadlock , QuasiLiveness, StableMarking, Liveness, OneSafe),
- Reachability Formulas (ReachabilityCardinality, ReachabilityFireability),
- CTL Formulas (CTLCardinality, CTLFireability),
- LTL Formulas (LTLCardinality, LTLFireability),
To avoid a too large disparity between models with numerous instances and those with only one, a normalization was applied so that the score, for an examination and a model, varies between 102 and 221 points. Therefore, providing a correct value may brings a different number of points according to the considered model. A multiplier was applied depending to the model category:
- ×1 for «Known» models,
- ×4 for «Surprise» models.
Let us introduce two «special» tools:
- 2020-gold is an hybrid tool made of the gold-medal for the 2020 edition for each examination. It is a way to evaluate the progress of participants since the last edition of the MCC.
- BVT (Best Virtual Tool) computes the union of all the values computed by all other tools. It is also always the fastest and the tool having the smallest memory footprint, based on what the participating tool performed. It is a way to evaluate the complementarity between tools by comparing it to the gold medal
5.1. Winners in the StateSpace Category
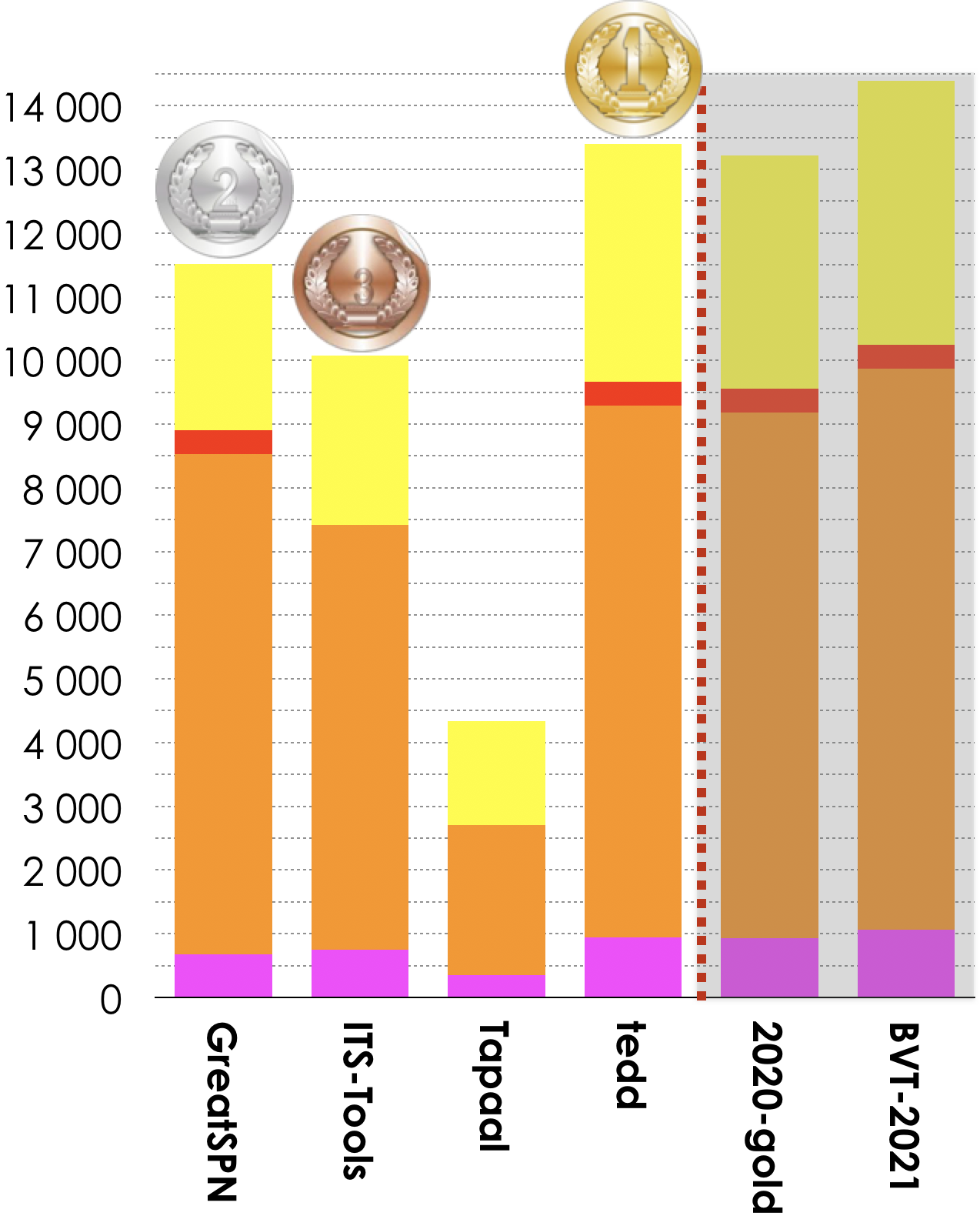
4 tools out of 7 participated in this examination. Results based on the scoring shown below is:
- TINA.tedd ranked first (13 402 pts),
- GreatSPN ranked second (11 518),
- ITS-Tools ranked third (10 077 pts).
Then, tools rank in the following order: Tapaal (4 333 pts). The Gold-medal of 2021 collected 13 220 pts. BVT (Best Virtual Tool) collected 14 390 points.
 |
  GreatSPN (fastest 252 times)  GreatSPN (less memory 535 times) |
| Estimated Tool Confidence rate for StateSpace (based on the «significant values» computed by tools) see section 6. for details |
|||
| Tool name | Reliability | Correct Values | «significant values» |
|---|---|---|---|
| GreatSPN | 99.82% | 3287 | 3293 |
| ITS-Tools | 100.00% | 2406 | 2406 |
| Tapaal | 99.02% | 908 | 917 |
| TINA.tedd | 100.00% | 3758 | 3758 |
| 2020-Gold | 100.00% | 3709 | 3709 |
5.2. Winners in the GlobalProperties Category
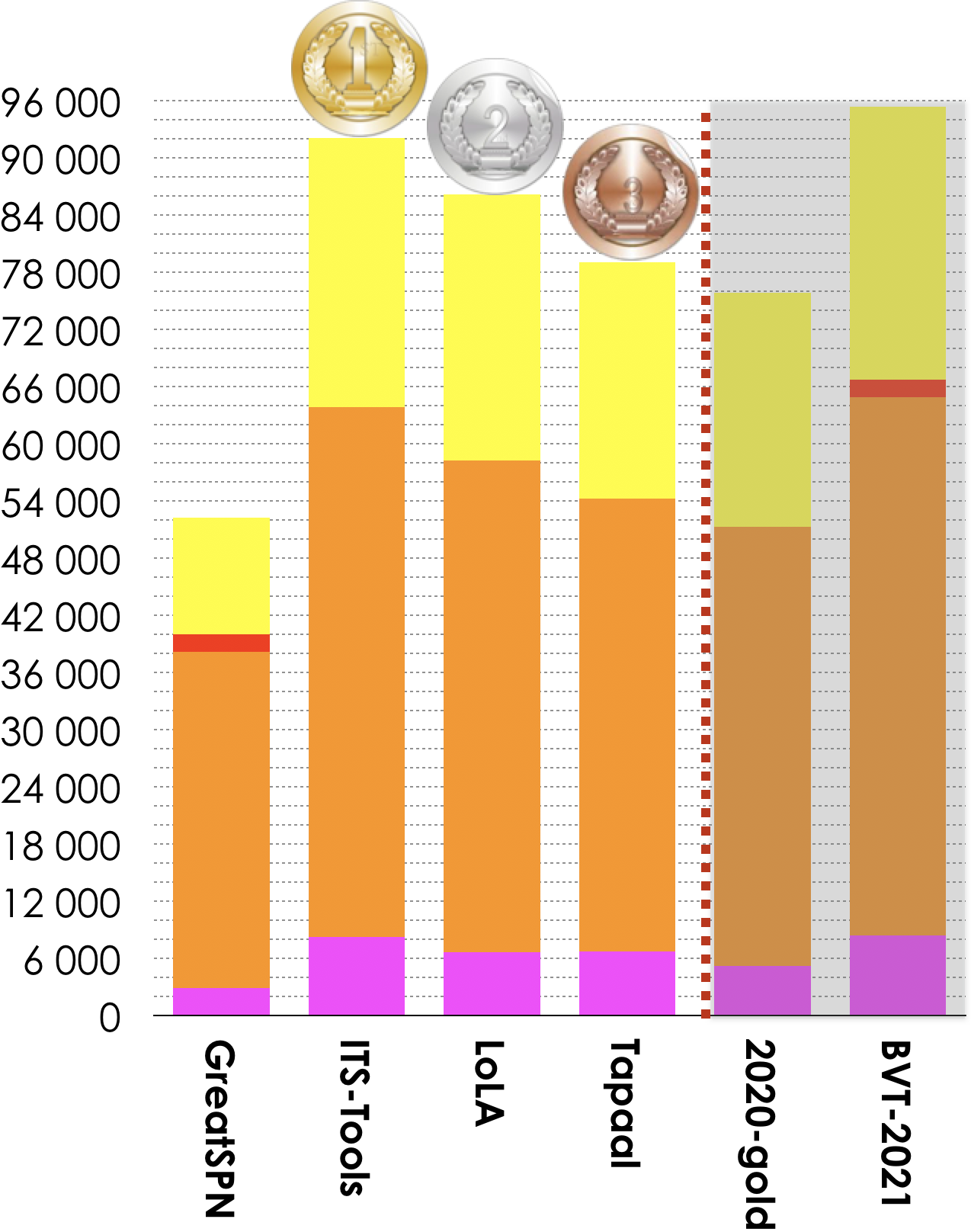
4 tools out of 7 participated in these examinations (ReachabilityDeadlock , QuasiLiveness, StableMarking, Liveness, OneSafe). Results based on the scoring shown below is:
- ITS-Tools ranked first (92 034 pts),
- LoLA ranked second (86 133 pts),
- Tapaal ranked third (79 013 pts).
Then, tools rank in the following order: GreatSPN (52 194 pts). The Gold-medal of 2020 collected 75 811 pts. BVT (Best Virtual Tool) collected 95 366 points.
 |
LoLA (fastest 5021 times) LoLA (less memory 3097 times) |
| Estimated Tool Confidence rate for GlobalPropertiesScores (based on the «significant values» computed by tools) see section 6. for details |
|||
| Tool name | Reliability | Correct Values | «significant values» |
|---|---|---|---|
| GreatSPN | 100.00% | 3666 | 3666 |
| ITS-Tools | 100.00% | 6401 | 6401 |
| LoLA | 99.84% | 6109 | 6119 |
| Tapaal | 99.72% | 5651 | 5667 |
| 2020-gold | 100.00% | 5221 | 5221 |
5.3. Winners in the UpperBounds Category
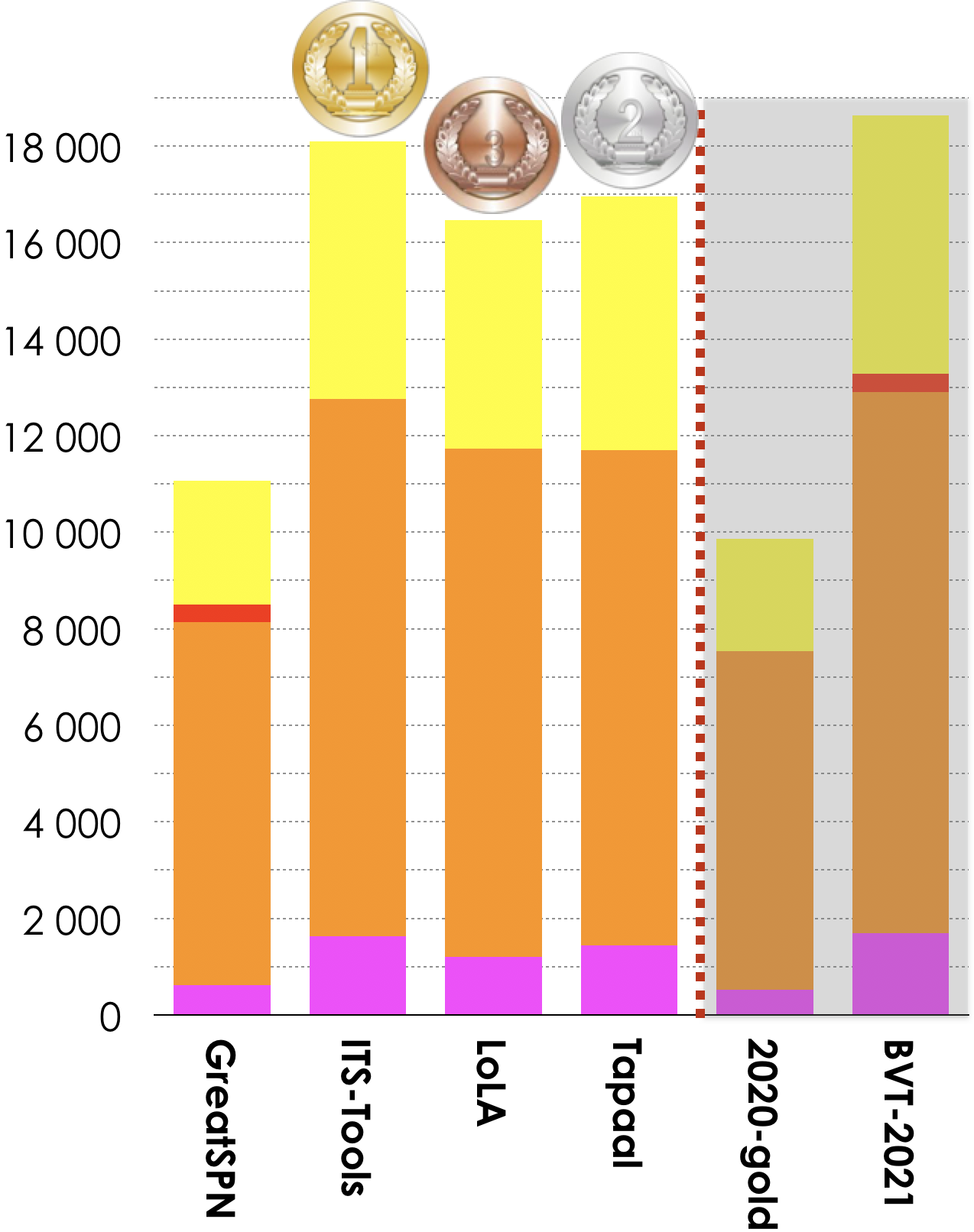
4 tools out of 7 participated in this examination. Results based on the scoring shown below is:
- ITS-Tools ranked first (18 091 pts),
- Tapaal ranked second (16 951 pts),
- LoLa ranked third (16 468 pts).
Then, tools rank in the following order: GratSPN (11 071 pts). The Gold-medal of 2020 collected 9 865 pts. BVT (Best Virtual Tool) collected 18 628 points.
 |
LoLA (fastest 898 times) LoLA (less memory 706 times) |
| Estimated Tool Confidence rate for UpperBound (based on the «significant values» computed by tools) see section 6. for details |
|||
| Tool name | Reliability | Correct Values | «significant values» |
|---|---|---|---|
| GreatSPN | 100.00% | 12550 | 12550 |
| ITS-Tools | 100.00% | 20471 | 20471 |
| LoLA | 100.00% | 19222 | 19222 |
| Tapaal | 100.00% | 19415 | 19415 |
| 2020-Gold | 97.73% | 11722 | 11994 |
5.4. Winners in the Reachability Formulas Category
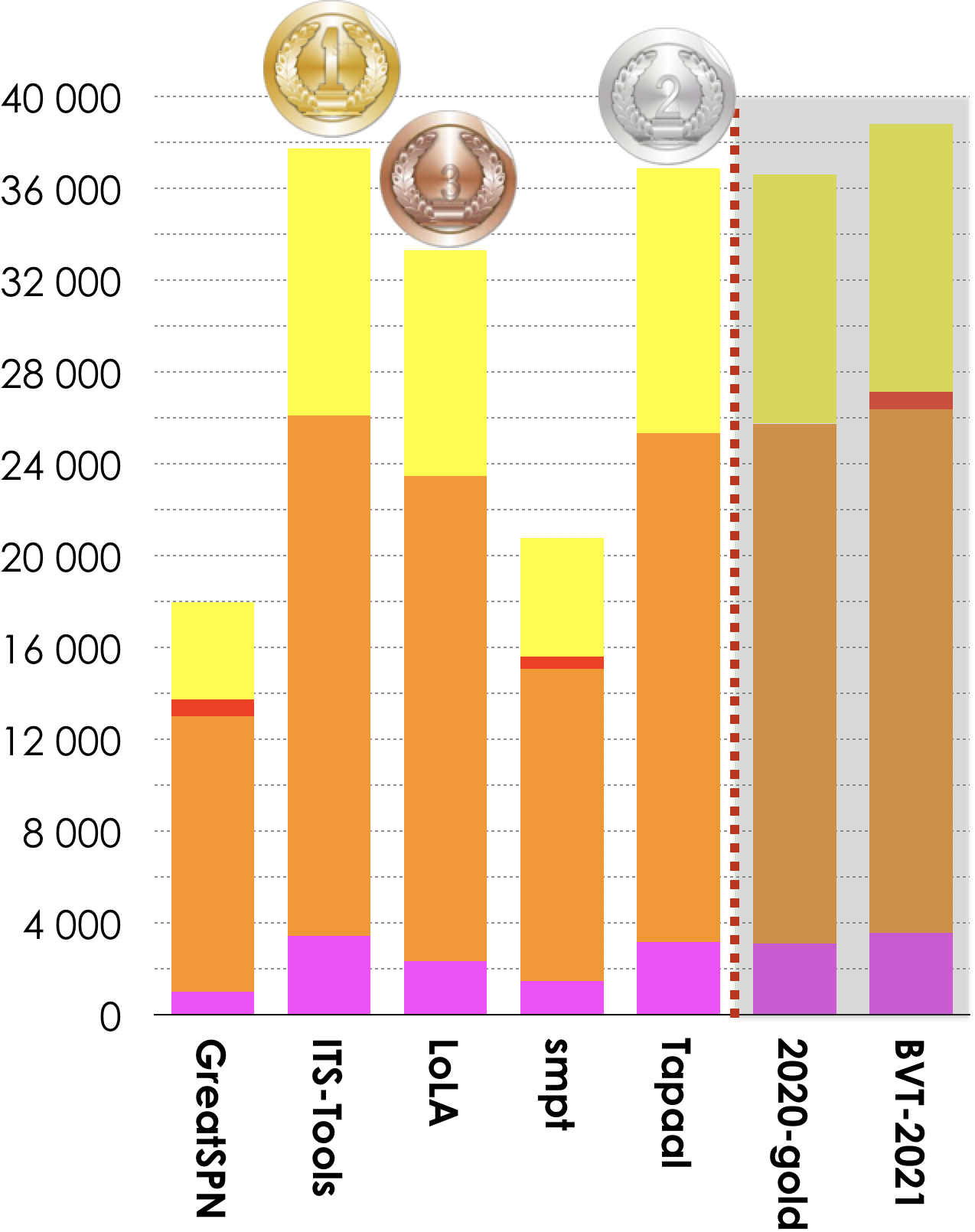
5 tools out of 7 participated in these examinations (ReachabilityCardinality and ReachabilityFireability). Results based on the scoring shown below is:
- ITS-Tools ranked first (37 733 pts),
- Tapaal ranked second (36 855 pts),
- LoLA ranked third (33 285 pts).
Then, tools rank in the following order: GreatSPN (17 966 pts), and smpt (20 751 pts). The Gold-medal of 2020 collected 36 590 pts. BVT (Best Virtual Tool) collected 38 806 points.
 |
LoLA (fastest 1298 times) Tapaal (less memory 1059 times) |
| Estimated Tool Confidence rate for Reachability (based on the «significant values» computed by tools) see section 6. for details |
|||
| Tool name | Reliability | Correct Values | «significant values» |
|---|---|---|---|
| GreatSPN | 100.00% | 19940 | 19940 |
| ITS-Tools | 100.00% | 43173 | 43173 |
| LoLA | 100.00% | 38153 | 38153 |
| smpt | 99.94% | 23335 | 23349 |
| Tapaal | 100.00% | 41742 | 41742 |
| 2020-Gold | 99.53% | 43285 | 43491 |
5.5. Winners in the CTL Formulas Category
4 tools out of 7 participated in these examinations (CTLCardinality and CTLFireability). Results based on the scoring shown below is:
- Tapaal ranked first (28 877 pts),
- ITS-Tools ranked second (20 229 pts),
- LoLA ranked third (18 506 pts).
Then, tools rank in the following order: GreatSPN (15 458 pts). The Gold-medal of 2020 collected 27 409 pts. BVT (Best Virtual Tool) collected 33 770 points.
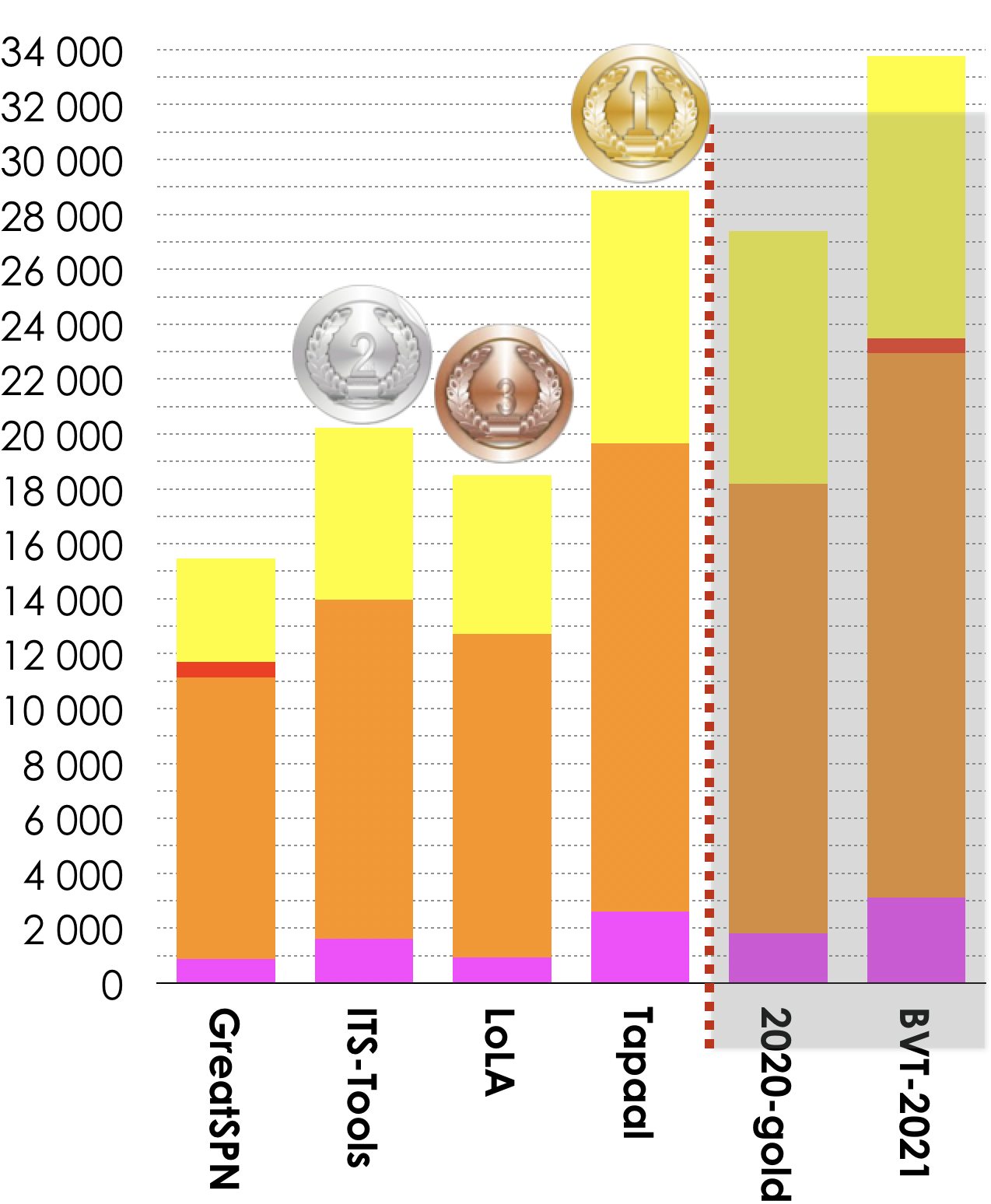 |
LoLA (fastest 157 times) GreatSPN (less memory 389 times) |
| Estimated Tool Confidence rate for CTL (based on the «significant values» computed by tools) see section 6. for details |
|||
| Tool name | Reliability | Correct Values | «significant values» |
|---|---|---|---|
| GreatSPN | 99.98% | 15907 | 15910 |
| ITS-Tools | 99.98% | 21210 | 21215 |
| LoLA | 97.57% | 21066 | 21591 |
| Tapaal | 99.99% | 31758 | 31762 |
| 2020-Gold | 99.98% | 29798 | 29803 |
5.6. Winners in the LTL Formulas Category
5 tools out of 7 participated in these examinations (LTLCardinality and LTLFireability). Results based on the scoring shown below is:
- Tapaal ranked first (35 692 pts),
- ITS-Tools ranked second (34 872 pts, ITS-Tools.M collected 17 102 pt),
- enPAC ranked third (31 745 pts).
Then, tools rank in the following order: LoLa (29 063 pts), and GreatSPN (16 979 pts). The Gold-medal of 2020 collected 28 697 pts. BVS (Best Virtual Score tool) collected 38 062 points.
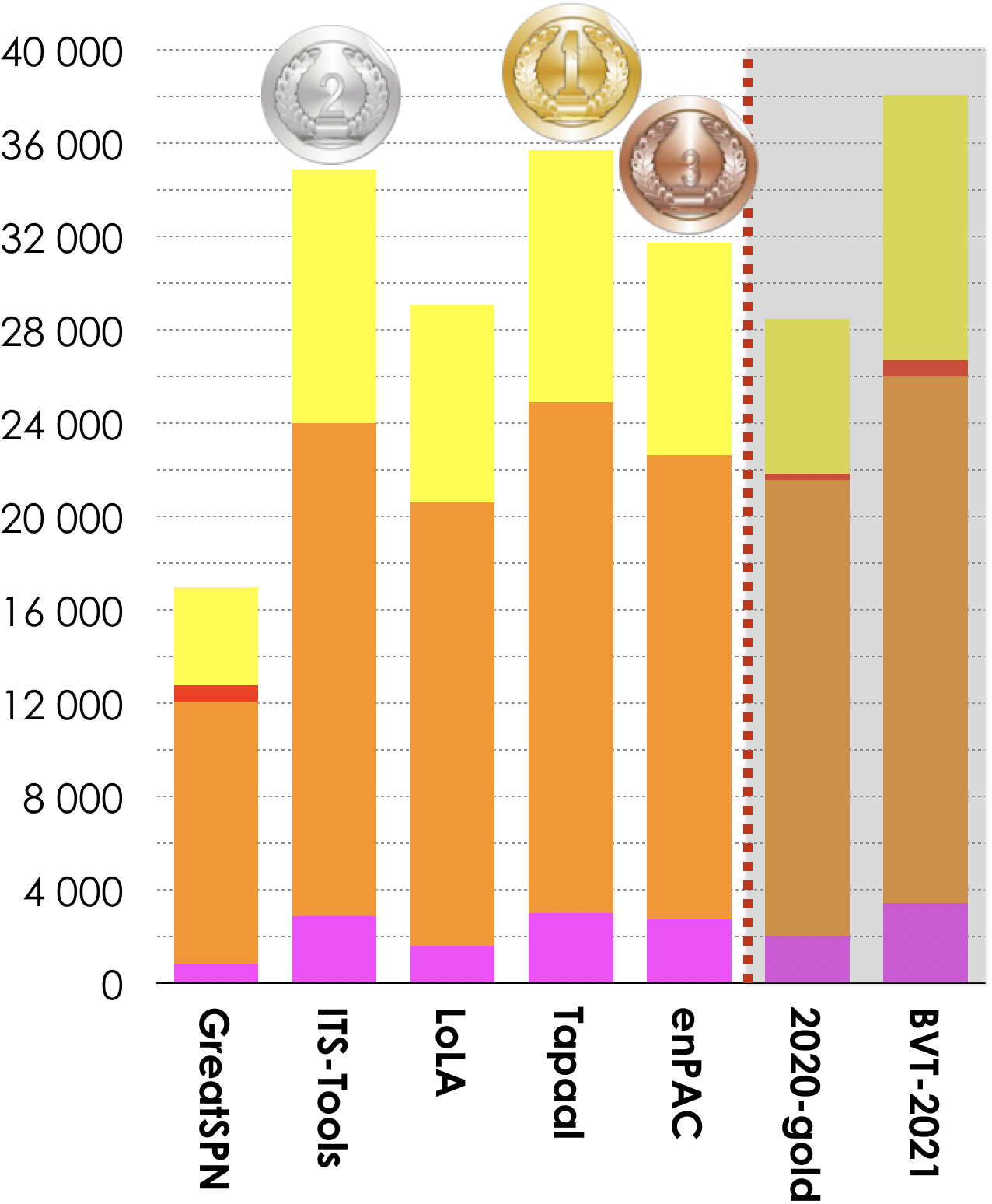 |
LoLA (fastest 548 times) Tapaal (less memory 849 times) |
| Estimated Tool Confidence rate for LTL (based on the «significant values» computed by tools) see section 6. for details |
|||
| GreatSPN | 98.38% | 19021 | 19334 |
| ITS-Tools | 99.99% | 39115 | 39118 |
| LoLA | 99.97% | 33087 | 33098 |
| Tapaal | 99.995% | 40298 | 40300 |
| enPAC | 99.97% | 37001 | 37011 |
| 2020-Gold | 99.65% | 34904 | 35025 |
6. Estimation of the Global Tool Confidence
A confidence analysis enforces the computation of «right results» based on the answers of participating tools. To do so, we considered each value provided in the contest (a value is a partial result such as the result of a formula or a number provided for state space, bound computation, etc.). To do so, we processed as follows:
- For each «line» (all tools for a given examination for a given instance), we selected all «significant values» where at least 3 tools do agree.
- Based on this subset of values, we computed the ratio between the selected values for the tool and the number of good answers hey provide for such values. This ratio gave us a tool confidence rate that is provided in the table below.
- This tool confidence rate rate was then applied to compute the scores presented in the dedicated section.
The table below provides, in first column, the computed confidence rates (that are naturally lower for tools where a bug was detected). Then, the table provides the number of correct results (column 2) out of the number of «significant values» selected for the tool (column 3). The last column shows the number of examinations (and their type) the tool was involved in.
| Estimated Tool Confidence rate (based on the «significant values» computed by tools) | ||||
| Tool name | Reliability | Correct Values | «significant values» | Involved Examinations |
|---|---|---|---|---|
| GreatSPN | 99.57% | 74 371 | 74 693 | 13 CTLCardinality, CTLFireability, LTLCardinality, LTLFireability, Liveness, OneSafe, QuasiLiveness, ReachabilityCardinality, ReachabilityDeadlock, ReachabilityFireability, StableMarking, StateSpace, UpperBounds |
| ITS-Tools | 99.99% | 132 776 | 132 784 | 13 CTLCardinality, CTLFireability, LTLCardinality, LTLFireability, Liveness, OneSafe, QuasiLiveness, ReachabilityCardinality, ReachabilityDeadlock, ReachabilityFireability, StableMarking, StateSpace, UpperBounds |
| LoLA | 99.54% | 117 636 | 118 183 | 12 CTLCardinality, CTLFireability, LTLCardinality, LTLFireability, Liveness, OneSafe, QuasiLiveness, ReachabilityCardinality, ReachabilityDeadlock, ReachabilityFireability, StableMarking, UpperBounds |
| smpt | 99.94% | 23 335 | 23 349 | 2 ReachabilityCardinality, ReachabilityFireability |
| Tapaal | 99.98% | 139 772 | 139 803 | 13 CTLCardinality, CTLFireability, LTLCardinality, LTLFireability, Liveness, OneSafe, QuasiLiveness, ReachabilityCardinality, ReachabilityDeadlock, ReachabilityFireability, StableMarking, StateSpace, UpperBounds |
| enPAC | 99.98% | 37 001 | 37 011 | 2 LTLCardinality, LTLFireability |
| TINA.tedd | 100.00% | 3 758 | 3 758 | 1 StateSpace |
| 2020-Gold | 99.53% | 128 639 | 129 243 | 13 CTLCardinality, CTLFireability, LTLCardinality, LTLFireability, Liveness, OneSafe, QuasiLiveness, ReachabilityCardinality, ReachabilityDeadlock, ReachabilityFireability, StableMarking, StateSpace, UpperBounds |