

1. Introduction
This page summarizes the results for the 2015 edition of the Model Checking Contest (MCC’2015). This page is divided in three sections:
- First, we list the qualified tools for the MCC'2015,
- Then, we provide some informations about the experimental conditions of the MCC'2015,
- Then, we present an access to details about results,
- Then, we provide the list of winners of the MCC'2015,
- Finally, we provide an attempt to evaluate tool reliability based on the comparison of the results provided in the contest.
2. List of Qualified Tools in 2015
Ten tools where submitted this year. They all successfully went through a qualification process requiring a total number of more than 25000 runs (each tool had to answer each examination for the first instance of each «known» model).
Data about these tools are summarized in the table below. For any tool, you can download the disk image that was provided with all its data. You may use these to reproduce measures locally and perform comparison with your own tool on the same benchmark.
Once downloaded, please unpack each disk image with the following command:
tar xjf image.vmdk.bz2
| Summary of the Participating Tools (alphabetical order) | |||||
| Tool name | Representative Author | Origin | Type of execution | Link to the submitted disk image | Reported Techniques |
|---|---|---|---|---|---|
| Cunf | C. Rodriguez | Univ. Paris 13 (France) | Sequential |  |
NET_UNFOLDING SAT_SMT |
| GreatSPN-Meddly | E. Amparore and M. Beccuti | Univ. Torino (Italy) | Sequential | |
DECISION_DIAGRAMS SYMMETRIES |
| ITS-Tools | Y. Thierry-Mieg | Univ. P. & M. Curie (France) | Parallel (collateral processing) | |
CEGAR DECISION_DIAGRAMS SAT_SMT TOPOLOGICAL USE_NUPN |
| LoLA 2.0 | K. Wolf | Univ. Rostock (Germany) | Sequential | |
EXPLICIT STATE_COMPRESSION STUBBORN_SETS SYMMETRIES TOPOLOGICAL |
| LTSMin | J. Meijer and J. van de Pol | Univ. Twente (Netherlands) | Parallel (parallel processing) | |
DECISION_DIAGRAMS STATIC_VARIABLE_REORDERING USE_NUPN |
| Marcie | C. Rohr and M. Heiner | Univ. Cottbus (Germany) | Sequential | |
DECISION_DIAGRAMS UNFOLDING_TO_PT |
| pnmc | A. Hamez | IRT Saint-Exupéry (France) | Sequential | |
DECISION_DIAGRAMS USE_NUPN |
| PNXDD | E. Paviot-Adet | Univ. P. & M. Curie (France) | Sequential | |
DECISION_DIAGRAMS SEQUENTIAL_PROCESSING TOPOLOGICAL |
| StrataGEM 0.5.0 | E. Lopez-Bobeda and D. Buchs | Univ. Genève (Switzerland) | Parallel (collateral processing) | |
DECISION_DIAGRAMS TOPOLOGICAL |
| TAPAAL | J. Srba | Univ. Aalborg (Denmark) | 4 variants (2 sequential, 2 parallel — collateral and parallel) | or |
EXPLICIT STATE_EQUATIONS STRUCTURAL_REDUCTION |
3. Experimental Conditions of the MCC'2015
Each tool was submitted to 12077 executions in various conditions (929 model/instances and 13 examination per model/instance) for which it could report: DNC (do not compete), CC (cannot compute) or the result of the query. These executions were handled by BenchKit, that was developed in the context of the MCC for massive testing of software. Then, from the raw data provided by BenchKit, some post-analysis scripts consolidated these and computed a ranking.
16 GB of memory were allocated to each virtual machine (both parallel and sequential tools) and a confinement of one hour was considered (execution aborted after one hour). So, a total of 169 078 runs (execution of one examination by the virtual machine) generated 24 Gbyte of raw data (essentially log files and CSV of sampled data)
The table below shows some data about the involved machines and their contribution to the computation of these results.
| Involved Machines and Execution of the Benchmarks | |||||
| bluewhale03 | Ebro | Quadhexa-2 | Small | Total | |
|---|---|---|---|---|---|
| Cores | 40 @ 2.8GHz | 64 @ 2.7GHz | 24 @ 2.66GHz | 5×24 @ 2.4GHz | - |
| Memory (GB) | 512 | 1024 | 128 | 5×64 | - |
| Used Cores sequential tools) | 31, 31 VM in // |
63, 63 VM in // |
7, 7 VM in // |
5×3, 5×3 VM in // |
- |
| Used Cores (parallel tools) | 36 (4 per VM), 9 VM in // |
60 (4 per VM), 15 VM in // |
20 (4 per VM), 5 VM in // |
5×12 (4 per VM), 5×3 VM in // |
- |
| Number of runs | 42 406 | 79 534 | 20 748 | 26 390 | 169 078 |
| Total CPU required | 400d, 12h, 48m, 36s | 713d, 04h, 30m, 32s | 175d, 17h, 25m, 55s | 249d, 19h, 19m, 20s | 1539d, 6h, 4m, 23s |
| Total CPU | about 4 years, 2 months and 18 days | - | |||
| Time spent to complete benchmarks | about 23 days and 12 hours | - | |||
| Estimated boot time of VMs + management (overhead) |
58 d, 16h, 59m | - | |||
We are please to thanks those who helped in the execution of tools:
- Bluewhale03 was made available by colleagues at Université de Genève,
- Ebro was made available by colleagues at Rostock University,
- Quadhexa-2 was made available by colleagues at Université Paris Ouest Nanterre,
- Small is one of the two clusters at LI6 (we got 5 nodes our of 23 there) Université Pierre & Marie Curie.
4. The Results of the MCC’2015
This First table below presents detailed results about the MCC'2015.
| Details about the Examinations in the MCC'2015 (part I): Details about Results and Scoring + Model Performance Charts |
||
| Details about Results and Scoring | Model Performance Charts | |
|---|---|---|
| StateSpace | ||
| ReachabilityBounds | ||
| ReachabilityCardinality | ||
| ReachabilityComputeBounds | ||
| ReachabilityDeadlock | ||
| ReachabilityFireability | ||
| ReachabilityFireabilitySimple | ||
| CTLCardinality | ||
| CTLFireability | ||
| CTLFireabilitySimple | ||
| No tool did participated in LTL examinations | ||
This Second table below presents some performance analysis related to tools during the MCC'2015.
| Details about the examinations in the MCC'2015 (part II)Tool Performance Charts | ||||
| All models |
«Surprise» models only |
«Stripped» models only |
«Known» models only |
|
|---|---|---|---|---|
| Cunf | ||||
| GreatSPN-Meddly | ||||
| ITS-Tools | ||||
| LoLA 2.0 | ||||
| LTSMin | ||||
| Marcie | ||||
| pnmc | ||||
| PNXDD | ||||
| StrataGEM0.5.0 | ||||
| TAPAAL (MC) | ||||
| TAPAAL (SEQ) | ||||
| TAPAAL-OTF (PAR) | ||||
| TAPAAL-OTF (SEQ) | ||||
You can download the full archive (1.5 GB compressed and 24 GB uncompressed) of the 169 078 runs processed to compute the results of the MCC'2015. This archive contains execution traces, execution logs and sampling, as well as a large CSV file (24 MB) that summarizes all the executions.
5. The Winners for the MCC'2015
This section presents the results for the main examinations that are:
- State Space generation,
- Reachability Formulas (ReachabilityBounds, ReachabilityCardinality, ReachabilityComputeBounds, ReachabilityDeadlock, ReachabilityFireability, ReachabilityFireabilitySimple),
- CTL Formulas (CTLCardinality, CTLFireability, CTLFireabilitySimple),
- LTL Formulas (LTLCardinality, LTLFireability, LTLFireabilitySimple),
- ×1 for «Known» models,
- ×3 for «Stripped» models,
- ×4 for «Surprise» models.
One problem was detected on the SmallOperatingSystem, a last minute change lead to a mistake reducing its marking graph to a single state. It is thus treated by all tools ;-). This will be corrected next time. Another consistency problem was detected between the QuasiCertifProtocol where the colored version was accidentally not equivalent to the P/T one (thus, consistency checks for this model have been disabled).
5.1. Winners in the StateSpace Category
This examination had the highest participation rate (11 tools). Results based on the scoring shown below is:
- Marcie was ranked first,
- pnmcwas ranked second,
- ITS-Toolswas ranked third.
Let us note that all the variants of TAPAAL were considered as one tool. We also discovered too late a problem with PNXDD (a java 8 configuration error resulted in numerous «Cannot Compute» answers) that was not detected during the qualification phase because it was only affecting «Stripped» and «Surprise». For next year, the qualification protocol will be extended to avoid such a situation. We also discovered that the LTSmin PNML front-end ignores inscriptions on arcs (i.e. it always assumes one token is consumed/produced per arc). This explains the errors in at least BridgeAndVehicles, PhaseVariation and DrinkVendingMachine.
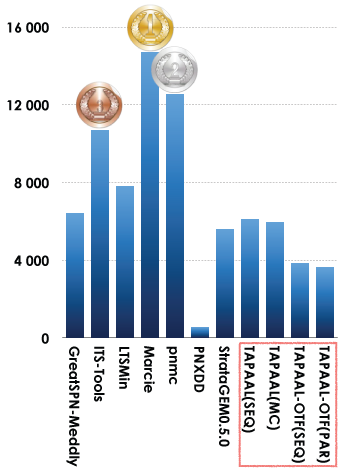
In some cases, the automatic analysis scripts (no one could handle such an amount of results manually ;-) are fooled by the way numeric values are displayed by tools (depending on the library they used). This can be observed in the instance «864» of Parking where all results can be considered as being true while the round algorithm is sometimes "fuzzy" (compare the execution report with the values used to get convinced). Next year, the minimum precision required for numeric values will be specified in the call for tool participation.
5.2. Winners in the Reachability Formulas Category
This examination was also quite successful with a hight participation rate (10 tools). Results based on the scoring shown below is:
- LoLA 2.0 was ranked first,
- TAPAALwas ranked second (the classic sequential version),
- Marciewas ranked third.
Bugs were detected by tool developers but too late to be considered (already several years of CPU were processed). In ITS-Tool, some student work was wrong when translating some king of formulas and the management of hierarchical NUPN data was inappropriate. Another problem was revealed in TAPAAP On the Fly. These two tools were intensively upgraded since their last participation to the MCC (2014 for TAPAAL and 2013 for ITS-Tools), this may explain the situation. A mistake was also discovered in the on-the-fly symbolic invariant detection in LTSmin's symbolic back-end (when optimizing formulas). This explains all errors in the ReachabilityCardinality category.
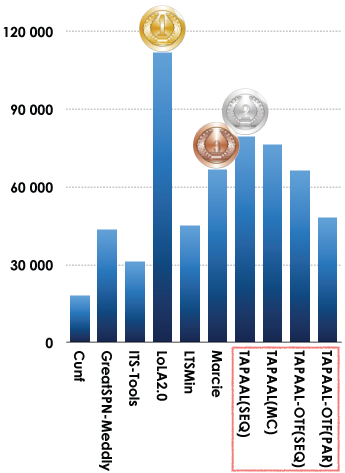
5.3. Winners in the CTL Formulas Category
Only two tools did participated. Results based on the scoring shown below is:
- Marcie was ranked first,
A bug was revealed in the translation of formulas for GreatSPN-Meddly. However, it was discovered by developers too late (already years of CPU were processed).

5.4. Winners in the LTL Formulas Category
In 2015 no tool competed in the LTL Formulas Category.
6. Estimation of Tool Reliability
This year, we tried to introduce some reliability analysis to enforce the computation of «right results» based on the answers of participating tools. To do so, we considered each value provided in the contest (a value is a partial result such as the result of a formula or a number provided for state space, bound computation, etc.). To do so, we processed as follows:
- For each «line» (all tools for a given examination for a given instance), we selected all «significant values» where at least 3 tools do agree.
- Based on this subset of values, we computed the ratio between the selected values for the tool and the number of good answers. This ratio gave us a tool reliability rate that is provided in the table below.
- This tool reliability rate was then applied to compute the scores presented in the dedicated section.
The table below provides, in first column, the computed reliability rate (that is naturally lower for tools where a bug was detected). Then, the table provides the number of correct results (column 2) out of the number of «significant values» selected for the tool (column 3). The last column shows the number of examination (and their type) the tool was involved in.
| Estimated Tool Reliability rate (based on the «significant values» computed by tools) | ||||
| Tool name | Reliability | Correct Values | «significant values» | Involved Examinations | Cunf | 96.96% | 4 728 | 4 875 | 3 (Reachability) | GreatSPN-Meddly | 62.30% | 11 966 | 19 206 | 10 (StateSpace, Reachability, CTL) | ITS-Tools | 64.05% | 10 890 | 17 003 | 4 (StateSpace, Reachability) | LoLA 2.0 | 97.80% | 25 796 | 26 378 | 6 (Reachability) | LTSMin | 79.13% | 13 995 | 17 687 | 5 (StateSpace, Reachability) | Marcie | 92.52% | 18 443 | 19 934 | 10 (StateSpace, Reachability, CTL) | pnmc | 99.59% | 741 | 744 | 1 (StateSpace) | PNXDD | 88.89% | 56 | 63 | 1 (StateSpace) | STrataGEM 0.5.0 | 100.00% | 243 | 243 | 1 (StateSpace) | TAPAAL (MC) | 99.75% | 23 247 | 23 306 | 7 (StateSpace, Reachability) | TAPAAL (SEQ) | 99.88% | 22 880 | 22 907 | 7 (StateSpace, Reachability) | TAPAAL-OTF (PAR) | 88.43% | 15 253 | 17 248 | 7 (StateSpace, Reachability) | TAPAAL-OTF (SEQ) | 96.19% | 19 001 | 19 733 | 7 (StateSpace, Reachability) |
|---|---|---|---|---|